This article is about the review for the tome Introduction to Algorithms (CLRS) 3rd Edition.
In this page, I will implement most of the algorithm in C/C++ (only the brief version, not intent to implement the template or generic version), and try to solve the exercises given by the book.
Reading a book with more than 1,000 pages of hardcore content is a nightmare, so I would not finish all chapters in this book.
Note that although I have written lots of notes and solutions, this page is not a panacea for those who have a nice sleep in class.
This is the new version, replacing the old one written in 2017.
PART I: FOUNDATIONS
2. Getting Started
2.1 Start with Insertion-Sort
Insertion sort is an efficient algorithm for sorting a small number of elements. The numbers that we wish to sort are called keys. Input: A sequence of n numbers ($a_1,a_2,\cdots,a_n$). Output: A permutation (reordering) ($a_1’,a_2’,\cdots,a_n’$) of the input sequence such that $a_1’ \leqslant a_2’ \leqslant \cdots \leqslant a_n$
pseudocode: is similar to some advanced programming languages like C/C++, Java, Python or Pascal and is easy to be rewritten into those languages.
for j = 2 to A.length
key = A[j]
i = j - 1
while i > 0 and A[i] > key
A[i+1] = A[i]
i = i - 1
A[i+1] = key
Notice that the first index of the array is 1 in pseudocode shown in this book while in most of the advanced language it is 0.
// notice that if A is a parameter of a function, we can't get the length in this way.int length =sizeof(A)/sizeof(int);for(int j=1; j<length; j++){int key = A[j];int i=j-1;while(i>-1&& A[i]>key){
A[i+1]= A[i];
i--;}
A[i+1]= key;}
For java, just change int length = sizeof(A) / sizeof(int); to int length = A.length.
Loop invariants and the correctness of insertion sort: The index j indicates the current element required to be taken out and be inserted to somewhere. At the start of each iteration, the subarray A[1…j-1] is in sorted order. And we state these properties of A[1…j-1] as a loop invariant.
We use loop invariants to help us understand why an algorithm is correct. We must show three things about a loop invariant: Initialization: It is true prior to the first iteration of the loop. Maintenance: If it is true before an iteration of the loop, it remains true before the next iteration. Termination: When the loop terminates, the invariant gives us a useful property that helps show that the algorithm is correct.
Now prove the correctness of the insertion sort. Initialization: When j=2, the subarray A[1…j-1] consists of only one element A[1]. Obviously it’s true that an array with one element is sorted. Maintenance: the body of the for loop works by moving A[j-1], A[j-2] and so on by one position to the right until it finds the proper position for A[j]. Then the subarray A[1…j] is in order. Termination: the loop terminates when j > A.length = n. So j will be n+1 when the loop ends. Then the subarray A[1…n] is in order, which shows that the algorithm is correct.
Exercises
2.1-1 Using Figure 2.2 as a model, illustrate the operation of INSERTION-SORT on the array A = ⟨31, 41, 59, 26, 41, 58⟩.
2.1-2 Rewrite the INSERTION-SORT procedure to sort into non-increasing instead of non-decreasing order.
Answer
for j = 2 to A.length
key = A[j]
i = j - 1
while i > 0 and A[i] < key
A[i+1] = A[i]
i = i - 1
A[i+1] = key
What I did is to make A[i] > key be A[i] < key. The modification of c++ or java code is corresponding to the pseudocode.
2.1-3 Consider the searching problem: Input: A sequence of n numbers $A = (a_1,a_2,\cdots,a_n)$ and a value v. Output: An index i such that v = A[i] or the special value NIL if v does not appear in A. Write pseudocode for linear search, which scans through the sequence, looking for v. Using a loop invariant, prove that your algorithm is correct. Make sure that your loop invariant fulfills the three necessary properties.
Answer
LINEAR-SEARCH(A,v)
for i=1 to A.length
if A[i] == v
return i
return NIL
Loop invariant: At the start of each iteration of the for loop, every element in the subarray A[1…j-1] is different to v. Initialization: Before the first loop iteration, the subarray is an empty array. Maintenance: During each loop iteration, we compare A[i] with v. If they are the same, i will be returned. Otherwise, continue to the next loop iteration. Termination: When i > length=n, the loop terminates and return NIL, which means there is no element the same as v in the array A.
2.1-4 Consider the problem of adding two n-bit binary integers, stored in two n-element arrays A and B. The sum of the two integers should be stored in binary form in an (n+1)-element array C. State the problem formally and write pseudocode for adding the two integers.
Answer Input: A.length = B.length = n. each element in A and B is either 0 or 1. Output: C[n+1] and the binary integer consists of C is the sum of two binary integers consist of A and B.
// In this article, we will use "int arr[]" instead of "int *arr" in the parameter list,// unless the array is dynamically allocated using malloc or new.voidadd(int A[],int B[],int C[],int n){int carry =0;for(int i = n -1; i >=0; i--){
C[i +1]=(A[i]+ B[i]+ carry)%2;if(A[i]+ B[i]+ carry >=2)
carry =1;else
carry =0;}
C[0]= carry;}
If we cannot use operator + and %, alternatively the logic operators are applicable to implement the adder like how we do in digital circuit. Consider when the carry or the result is 1. If the number of the sum of A[i], B[i] and carry is odd, then C[i] is 1, otherwise 0. Written in boolean expression: $res = ABC + A\bar B\bar C + \bar A B \bar C + \bar A\bar B C = A \oplus B \oplus C$ $carry = ABC + AB\bar C + A\bar BC + \bar ABC = AB + AC + BC$ (C is the carry bit of the last adder unit.)
To simplify the analysis, we assume a RAM model with one processor. We don’t care about memory-hierarchy like cache and virtual memory.
In general, the time taken by an algorithm grows with the size of the input, so it is traditional to describe the running time of a program as a function of the size of its input.
Take INSERTION-SORT as an example.
for j = 2 to A.length // c_1
key = A[j] // c_2
i = j - 1 // c_3
while i > 0 and A[i] < key // c_4
A[i+1] = A[i] // c_5
i = i - 1 // c_6
A[i+1] = key // c_7
Assume that the line j costs a $c_j$. Individual $c_2,c_3,c_5,c_6,c_7$ cost a constant time. The time for $c_1$ and $c_4$ depend on the input size n. $$ T(n) = c_1 n + c_2(n-1) + c_3(n-1) + c_4\sum_{j=2}^n t_j + c_5\sum_{j=2}^n(t_j-1) + c_6\sum_{j=2}^n(t_j-1) + c_7(n-1) $$
Even for inputs of a given size, an algorithm’s running time may depend on which input of that size is given. For example, the best case for INSERTION-SORT is when the array is already sorted. Then the 5th and 6th lines will never be executed. Then the best-case running time is $$ \begin{align} T(n) &= c_1 n + c_2(n-1) + c_3(n-1) + c_4(n-1) + c_7(n-1) \\ &= (c_1 + c_2 + c_3 + c_4 + c_7)n - (c_2 + c_3 + c_4 + c_7) \end{align} $$ We can express this running time as $an + b$ for constants a and b that depend on the statement costs $c_i$ ; it is thus a linear function of n.
If the array is in reverse sorted order — that is, in decreasing order—the worst case results. Then the 5th and the 6th lines will always be executed in each for loop iteration. The 4th line will be executed $\sum\limits_{j=2}^{n}j$ times and the 5th and the 6th lines will be executed $\sum\limits_{j=2}^{n}(j-1)$ times. So the running time of INSERTION-SORT in the worst case is $$ \begin{align} T(n) &= c_1 n + c_2(n-1) + c_3(n-1) + c_4\sum_{j=2}^{n}j + c_5\sum_{j=2}^{n}(j-1) + c_6\sum_{j=2}^{n}(j-1) + c_7(n-1) \\ &= c_1 n + c_2(n-1) + c_3(n-1) + c_4\left(\frac{n(n+1)}{2}-1\right) + c_5\left(\frac{n(n-1)}{2}\right) + c_6\left(\frac{n(n-1)}{2}\right) + c_7(n-1) \\ &= (\frac{c_4}{2} + \frac{c_5}{2} + \frac{c_6}{2})n^2 + (c_1 + c_2 + c_3 + \frac{c_4}{2} - \frac{c_5}{2} - \frac{c_6}{2} + c_7)n - (c_2 + c_3 + c_4 + c_7) \\ &= an^2 + bn + c \end{align} $$ which is a quadratic function of n.
We usually concentrate on the worst case because it provides a guarantee that the algorithm will never take any longer. For some algorithms, the worst case occurs fairly often. For example, in searching a database for a particular piece of information, the searching algorithm’s worst case will often occur when the information is not present in the database. In some particular cases, we may be interested in the average-case running time of an algorithm. The average case is often roughly as bad as the worst case.
Order of Growth
We use some abstractions to simplify the analysis. We can ignore the actual cost of each statement. We can also ignore the lower-order terms and the leading term’s constant coefficient. So we say the insertion sort has a worst-case running time of $\Theta(n^2)$.
We usually consider one algorithm to be more efficient than another if its worst-case running time has a lower order of growth. Due to constant factors and lower-order terms, an algorithm whose running time has a higher order of growth might take less time for small inputs than an algorithm whose running time has a lower order of growth. But for large enough inputs, a $\Theta(n^2)$ algorithm, for example, will run more quickly in the worst case than a $\Theta(n^3)$ algorithm.
Exercises
2.2-1 Express the function $\begin{gather} \cfrac{n^3}{1000} - 100n^2 - 100n + 3 \end{gather}$ in terms of Θ-notation.
Answer $\Theta(n^3)$
2.2-2 Consider sorting n numbers stored in array A by first finding the smallest element of A and exchanging it with the element in A[1]. Then find the second-smallest element of A, and exchange it with A[2]. Continue in this manner for the first n - 1 element of A. Write pseudocode for this algorithm, which is known as selection sort. What loop invariant does this algorithm maintain? Why does it need to run for only the first n - 1 elements, rather than for all n elements? Give the best-case and worst-case running times of selection sort in Θ-notation.
Answer
for j=1 to A.length - 1
index_of_min = j
min = A[j]
// search for minimum for A[j...n]
for i=j+1 to A.length
if A[i] < min
index_of_min = i
min = A[i]
// swap two numbers
A[index_of_min] = A[j]
A[j] = min
int n =sizeof(A)/sizeof(int);for(int j=0; j<n-1; j++){int index_of_min = j;int min = A[j];for(int i=j+1; i<n; i++){if(A[i]< min){
index_of_min = i;
min = A[i];}}
A[index_of_min]= A[j];
A[j]= min;}
Loop invariant: At the start of each iteration of the outer for loop, the subarray A[1…j-1] is sorted.
It needs to run for only the first n-1 elements rather than for all n elements because after each loop iteration, every element in A[1…j] is less than elements in A[j…n]. So after n-1 loop iteration, the last element A[n] is certainly the largest one thus the array A is sorted.
The best case is when the array is already sorted. The best-case running time is $\Theta(n^2)$.
The worst case is when the array is reversed sorted. The worst-case running time is $\Theta(n^2)$.
2.2-3 Consider linear search again (see Exercise 2.1-3). How many elements of the input sequence need to be checked on the average, assuming that the element being searched for is equally likely to be any element in the array? How about in the worst case? What are the average-case and worst-case running times of linear search in Θ-notation? Justify your answers.
Answer In average case, half of the elements will be searched. In the worst case, all elements will be searched. Both of the average-case and worst-case running time are $\Theta(n)$.
2.2-4 How can we modify almost any algorithm to have a good best-case running time?
Answer Return the precomputed result if the input matches some special cases.
2.3 Designing Algorithms
We can choose from a wide range of algorithm design techniques. For insertion sort, we used an incremental approach. Another design approach is called divide-and-conquer. We can use it to design a sorting algorithm whose worst-case running time is much less than that of insertion sort and is easy to determine.
2.3.1 The Divide-and-conquer Approach
Many useful algorithms are recursive in structure: to solve a given problem, they call themselves recursively one or more times to deal with closely related sub-problems.
Algorithms following a divide-and-conquer approach break the problem into several sub-problems that are similar to the original problem but smaller in size, solve the sub-problems recursively, and then combine these solutions to create a solution to the original problem.
The merge sort algorithm closely follows the divide-and-conquer paradigm: Divide: Divide the n-element sequence to be sorted into two subsequences of n/2 elements each. Conquer: Sort the two subsequences recursively using merge sort. Combine: Merge the two sorted subsequences to produce the sorted answer.
Define an auxiliary procedure MERGE(A,p,q,r), where A is an array and p, q, and r are indices into the array such that $p \leqslant q < r$. The procedure assumes that the subarrays A[p…q] and A[q+1…r] are in sorted order. It merges them to form a single sorted subarray that replaces the current subarray A[p…r].
The first element of each subarray is the smallest element in each subarray. So we can compare which one is smaller and put it into the first position of the result array. Then compare the smallest element in one subarray and the second-smallest element in another subarray whose smallest element has already been taken. Then put the second element into the second place of the merged array. Repeat this step until one subarray is empty, then put another subarray to the right of the merged array. Each step takes constant time. Since we perform at most n basic steps, merging takes $\Theta(n)$ time.
To avoid checking if the subarray is empty in every step, we place on a sentinel element to the right of every subarray to simplify the code. A sentinel elements is a special value. Here we use ∞ as the sentinel value.
MERGE(A,p,q,r)
n1 = q - p + 1
n2 = r - q
let L[1...n1+1] and R[1...n2+1] be new arrays
for i = 1 to n1
L[i] = A[p+i-1]
for j = 1 to n2
R[j] = A[q+j]
L[n1+1] = ∞
R[n2+1] = ∞
i = 1
j = 1
for k = p to r
if L[i] <= R[j]
A[k] = L[i]
i = i + 1
else
A[k] = R[j]
j = j + 1
Proof of correctness: Initialization: Prior to the first iteration of the loop, we have k = p, so that the subarray A[p…k-1] is empty. This empty subarray contains the $k - p = 0$ smallest elements of L and R, and since i = j = 1, both L[i] and R[j] are the smallest elements of their arrays that have not been copied back into A. Maintenance: To see that each iteration maintains the loop invariant, let us first suppose that $L[i] \leqslant R[j]$. Then L[i] is the smallest element not yet copied back into A. Because A[p…k-1] contains the $k - p$ smallest elements, after copying L[i] into A[k], the subarray A[p…k] will contain the $k-p+1$ smallest elements. Incrementing k (in the for loop update) and i reestablishes the loop invariant for the next iteration. Termination: At termination, $k=r+1$. By the loop invariant, the subarray A[p…k-1], which is A[p…r], contains the $k-p=r-p+1$ smallest elements of L[1…n1+1] and R[1…n2+1], in sorted order. The arrays L and R together contain $n1 + n2 + 2 = r - p + 3$ elements. All but the two largest sentinels have been copied back into A.
If the length of the subarray is 1, it’s true that the subarray is sorted. We can subdivide the subarray again and again until its length is 1. Then merge them so that we can get the sorted array.
MERGE-SORT(A,p,r)
if p < r
q = ⌊(p+r)/2⌋
MERGE-SORT(A,p,q)
MERGE-SORT(A,q+1,r)
MERGE(A,p,q,r)
voidmerge_sort(int[],int,int);voidmerge_sort(int A[],int p,int r){if(p < r-1){int q =(p+r)/2;merge_sort(A, p, q);merge_sort(A, q, r);merge(A, p, q, r);}}
2.3.2 Analyzing Divide-and-Conquer Algorithms
When an algorithm contains a recursive call to itself, we can often describe its running time by a recurrence equation or recurrence.
Let T(n) be the running time on a problem of size n.
If the problem size is small enough ($n \leqslant c$ for some constant c), the straightforward solution takes constant time, which we write as $\Theta(1)$.
Suppose that our division of the problem yields a subproblems, each of which is 1=b the size of the original. It takes time $T(\frac{n}{b})$ to solve one subproblem of size $\frac{n}{b}$, and so it takes time $aT(\frac{n}{b})$ to solve a of them.
If we take D(n) time to divide the problem into subproblems and C(n) time to combine the solutions to the subproblems into the solution to the original problem, we get the recurrence $$ T(n)= \begin{align*} \begin{cases} \Theta(1) & \text{ if } n \leqslant c \\ aT(\cfrac{n}{b}) + D(n) + C(n) & \text{ otherwise} \end{cases} \end{align*} $$
Although the code runs correctly even if the number of the elements is not even, we can assume that the original size is a power of 2 to simplify the analysis. Divide: The divide step just computes the middle of the subarray, which takes constant time. Thus, $D(n)=\Theta(1)$. Conquer: We recursively solve two subproblems, each of size $\frac{n}{2}$, which contributes $2T(\frac{n}{2})$ to the running time. Combine: We have already noted that the MERGE procedure on an n-element subarray takes time $C(n)=\Theta(n)$. Then $$ T(n)= \begin{align*} \begin{cases} \Theta(1) & \text{ if } n = 1 \\ 2T(\cfrac{n}{2}) + \Theta(n) & \text{ if } n > 1 \end{cases} \end{align*} \tag{2.1} $$
We can rewrite recurrence (2.1) as $$ T(n)= \begin{align*} \begin{cases} c & \text{ if } n = 1 \\ 2T(\cfrac{n}{2}) + cn & \text{ if } n > 1 \end{cases} \end{align*} \tag{2.2} $$
Assume that n is large enough, then we can divide $T(n)$ into two smaller $T(\frac{n}{2})$. We can continue subdividing $T(\frac{n}{2})$ into two smaller $T(\frac{n}{4})$. As we continue expanding each node we can get a recursion tree. The total number of levels of the recursion tree is $\lg{n}+1$, where n is the number of leaves, corresponding to the input size. In asymptotic analysis, we consider $\log_2$ as $\lg$.
Next, we add the costs across each level of the tree. The top level has total cost $cn$, the next level down has total cost $c(\frac{n}{2}) + c(\frac{n}{2}) = cn$ In general, the level i below the top has $2^i$ nodes, each node contributes a cost of $c(\frac{n}{2^i})$. So the level i below the top has total cost $2^i c(\frac{n}{2^i})=cn$. The bottom level has n nodes, each contributing a cost of c, for a total cost of $cn$.
To compute the total cost represented by the recurrence (2.2), we simply add up the costs of all the levels. The recursion tree has $\lg{n}+1$ levels, each costing $cn$, for a total cost of $cn(\lg{n}+1) = cn\lg(n) + cn$. Ignoring the low-order term and the constant c gives the desired result of $\Theta(n\lg n)$.
Exercises
2.3-1 Using Figure 2.4 as a model, illustrate the operation of merge sort on the array $A=\langle 3, 41, 52, 26, 38, 57, 9, 49 \rangle$.
2.3-2 Rewrite the MERGE procedure so that it does not use sentinels, instead stopping once either array L or R has had all its elements copied back to A and then copying the remainder of the other array back into A.
Answer
MERGE(A,p,q,r)
n1 = q - p + 1
n2 = r - q
let L[1...n1] and R[1...n2] be new arrays
for i = 1 to n1
L[i] = A[p+i-1]
for j = 1 to n2
R[j] = A[q+j]
i = 1
j = 1
for k = p to r
if i > n1
A[k] = R[j]
j = j + 1
else if j > n2
A[k] = L[i]
i = i + 1
else if L[i] <= R[j]
A[k] = L[i]
i = i + 1
else
A[k] = R[j]
j = j + 1
2.3-3 Use mathematical induction to show that when n is an exact power of 2, the solution of the recurrence $ T(n) = \begin{cases} 2 & \text{if } n = 2, \\ 2T(\cfrac{n}{2}) + n & \text{if } n = 2^k, \text{for } k > 1 \end{cases} $ is $T(n) = n\lg n$.
2.3-4 We can express insertion sort as a recursive procedure as follows. In order to sort A[1…n], we recursively sort A[1…n-1] and then insert A[n] into the sorted array A[1…n-1]. Write a recurrence for the worst-case running time of this recursive version of insertion sort.
Answer The time costed by inserting A[n] into the sorted array A[1…n] in the worst case: $\Theta(n)$. The recurrence: $$ T(n) = \begin{align*} \begin{cases} 1 & \text{if }n = 1, \\ T(n-1) + \Theta(n) & \text{if }n > 1 \end{cases} \end{align*} $$ The total time: $\Theta(n^2)$.
2.3-5 Referring back to the searching problem (see Exercise 2.1-3), observe that if the sequence A is sorted, we can check the midpoint of the sequence against v and eliminate half of the sequence from further consideration. Binary search is an algorithm that repeats this procedure, halving the size of the remaining portion of the sequence each time. Write pseudocode, either iterative or recursive, for binary search. Argue that the worst-case running time of binary search is $\Theta(\lg n)$.
Answer Iterative:
BINARY-SEARCH(A, v)
from = 1
to = A.length
while from <= to
mid = ⌊(from + to) / 2⌋
if A[mid] == v
return mid
if A[mid] > v
to = mid
else
from = mid
return NIL
intbinary_search(int A[],int length,int v){int from =0;int to = length;while(from <= to){int mid =(from + to)/2;if(A[mid]== v)return mid;if(A[mid]> v)
to = mid -1;else
from = mid +1;}return-1;}
Recursive:
BINARY-SEARCH(A, v, from, to)
if from > to
return NIL
mid = ⌊(from + to) / 2⌋
if A[mid] = v
return mid
else if A[half] > v
return BINARY-SEARCH(B, v, from, mid)
else
return BINARY-SEARCH(B, v, mid, to)
For the worst case, the recurrence is $$ T(n)= \begin{align*} \begin{cases} \Theta(1) & \text{ if } n = 1 \\ T(\cfrac{n}{2}) + \Theta(1) & \text{ if } n > 1 \end{cases} \end{align*} $$ The total time $T(n)=\Theta(\lg n)$.
2.3-6 Observe that the while loop of lines 5–7 of the INSERTION-SORT procedure in Section 2.1 uses a linear search to scan (backward) through the sorted subarray A[1…j-1]. Can we use a binary search (see Exercise 2.3-5) instead to improve the overall worst-case running time of insertion sort to $\Theta(n\lg n)$?
Answer No. Binary search can find a place to insert, but we still need to shift all elements greater than the number A[j] backward. It takes $\Theta(\lg j + j)=\Theta(j)$ and the total time is $\Theta(n^2)$.
2.3-7 * Describe a $\Theta(n\lg n)$-time algorithm that, given a set S of n integers and another integer x, determines whether or not there exist two elements in S whose sum is exactly x.
Answer Sort the array using merge sort, which takes $\Theta(n\lg n)$. For any number y in sorted array, search for another number $(x-y)$ in the sorted array using binary search, which takes $\Theta(\lg n)$. The total time: $\Theta(n\lg n) + n\Theta(\lg n) = \Theta(n\lg n)$.
SEARCH(S, x)
A = MERGE-SORT(S, 1, S.length)
for i=1 to A.length
y = A[i]
if BINARY-SEARCH(A, x-y, i, A.legnth) != NIL
return true
return false
bool search(int S[],int length,int x){merge_sort(S,0, length);for(int i=0; i<length; i++){int y = S[i];if(binary_search(S, x - y, i, length)!=-1)return true;}return false;}
If we want to know the exact numbers:
voidsearch(int S[],int length,int x){merge_sort(S,0, length);
bool found = false;for(int i=0; i<length; i++){int y = S[i];int found_index =binary_search(S, x - y, i, length);if(found_index !=-1){
found = true;printf("%d+%d=%d", y, A[found_index], x)}}if(!found)printf("There is no pair of numbers to be summed up to %d", x);}
Problems
2-1 Insertion sort on small arrays in merge sort Although merge sort runs in $\Theta(n\lg n)$ worst-case time and insertion sort runs in $\Theta(n^2)$ worst-case time, the constant factors in insertion sort can make it faster in practice for small problem sizes on many machines. Thus, it makes sense to coarsen the leaves of the recursion by using insertion sort within merge sort when subproblems become sufficiently small. Consider a modification to merge sort in which $\frac{n}{k}$ sublists of length k are sorted using insertion sort and then merged using the standard merging mechanism, where k is a value to be determined. a. Show that insertion sort can sort the $\frac{n}{k}$ sublists, each of length k, in $\Theta(nk)$ worst-case time. b. Show how to merge the sublists in $\Theta(n\lg\frac{n}{k})$ worst-case time. c. Given that the modified algorithm runs in $\Theta(nk + n\lg\frac{n}{k})$ worst-case time, what is the largest value of k as a function of n for which the modified algorithm has the same running time as standard merge sort, in terms of Θ-notation? d. How should we choose k in practice?
Answer
a. The worst-case time for insertion sort to sort a sublist of length k is $\Theta(k^2)$, so the worst-case time to sort $\frac{n}{k}$ sublists is $\frac{n}{k}\Theta(k^2) = \Theta(nk)$.
b. There are $\lg\frac{n}{k}$ levels and each level takes $\Theta(n)$ to merge. So the worse-case time is $\Theta(n\lg\frac{n}{k})$.
c. When the modified algorithm has the same running time as standard merge sort, we have $$\Theta(nk + n\lg\frac{n}{k}) = \Theta(nk + n\lg n - n\lg k) = \Theta(n\lg n)$$ To let $(nk + n\lg n - n\lg k)$ grow as fast as $n\lg n$, $nk$ must grow slower or as fast as $n\lg n$. Therefore $k \leqslant \lg n$. So the largest value of k is $\lg n$.
d. Choose k be the largest length of sublist on which insertion sort is faster than merge sort. To let $c_1 k^2 \leqslant c_2\lg k$, that is, to let $k \leqslant \frac{c_2}{c_1}\lg k$.
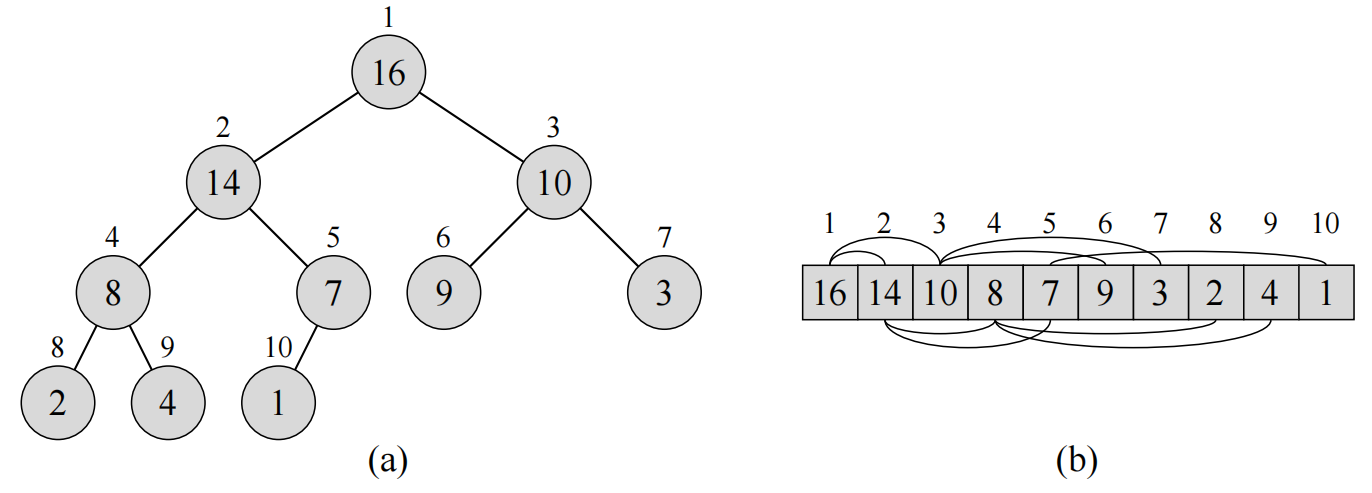
2-2 Correctness of bubblesort Bubblesort is a popular, but inefficient, sorting algorithm. It works by repeatedly swapping adjacent elements that are out of order. BUBBLESORT(A)
for i = 1 to A.length - 1
for j = A.length downto i + 1
if A[j] < A[j - 1]
exchange A[j] with A[j - 1]
a. Let A’ denote the output of BUBBLESORT(A). To prove that BUBBLESORT is correct, we need to prove that it terminates and that $$ A’[1] \leqslant A’[2] \leqslant \cdots A’[n] \tag{2.3} $$ where n=A.length. In order to show that BUBBLESORT actually sorts, what else do we need to prove? The next two parts will prove inequality (2.3). b. State precisely a loop invariant for the for loop in lines 2–4, and prove that this loop invariant holds. Your proof should use the structure of the loop invariant proof presented in this chapter. c. Using the termination condition of the loop invariant proved in part (b), state a loop invariant for the for loop in lines 1–4 that will allow you to prove inequality (2.3). Your proof should use the structure of the loop invariant proof presented in this chapter. d. What is the worst-case running time of bubblesort? How does it compare to the running time of insertion sort?
Answer
a. we need to prove that the elements in A’ are the elements in A.
b. Loop invariant: At the start of each iteration of the for loop of line 2-4, the element A[j] is the smallest element in subarray A[j…n] where $j=i+1$. Initialization: Initially the subarray contains only the last element A[n], which is the smallest element of the subarray. Maintenance: After the iteration the element A[j-1] is the smallest element in subarray A[j-1…n]. Termination: The loop terminates when $i=j$. After iteration, the element A[i] is the smallest element in A[i…n] and A[i…n] consists of the elements originally in A[i…n] before entering the loop.
c. Loop invariant: At the start of each iteration of the for loop of lines 1-4, the subarray A[1…i-1] consists of the i-1 smallest elements in A[1…n] in sorted order. Initialization: Initially the subarray A[1…i-1] is empty. Maintenance: In the beginning of the outer loop, the subarray A[1…i-1] consists of elements that are less than the elements of A[i…n], in sorted order. After the end of the outer loop, the subarray A[1…i] will consist of elements that are less than the elements in A[i+1…n], in sorted order. Termination: The loop terminates when i=A.length. And the subarray will consist of all elements in original A, but in sorted order.
d. The worst-case running time of the bubblesort is the same as insertion sort, which is $\Theta(n^2)$.
2-3 Correctness of Horner’s rule The following code fragment implements Horner’s rule for evaluating a polynomial $$ P(x) \begin{align} &= \sum_{k=0}^{n}a_k x^k \\ &= a_0 + x(a_1 + x(a_2 + \cdots + x(a_{n-1} + xa_n)\cdots)) \end{align} $$ given the coefficients $a_0,a_1,\cdots,a_n$ and a value for x:
y = 0
for i = 0 downto 0
y = aᵢ + x·y
a. In terms of Θ-notation, what is the running time of this code fragment for Horner’s rule? b. Write pseudocode to implement the naive polynomial-evaluation algorithm that computes each term of the polynomial from scratch. What is the running time of this algorithm? How does it compare to Horner’s rule? c. Consider the following loop invariant: At the start of each iteration of the for loop of lines 2–3, $$ y = \sum_{k=0}^{n-(i+1)}a_{k+i+1}x^k $$ Interpret a summation with no terms as equaling 0. Following the structure of the loop invariant proof presented in this chapter, use this loop invariant to show that, at termination, $y=\sum\limits_{k=0}^{n} a_x x^k$ d. Conclude by arguing that the given code fragment correctly evaluates a polynomial characterized by the coefficients $a_0,a_1,\cdots,a_n$.
Answer
a. $\Theta(n)$
b.
y = 0
for i=0 to n
z = 1
for j=1 to i
z = z * x
y = y + aᵢ·z
The running time is $\Theta(n^2)$, which is slower than Horner’s rule.
c. Initialization: It’s trivial that the summation has no term because y=0 at the start. Maintenance: According to the loop invariant, in the end of the i-th iteration, we have $$ \begin{align} y &= a_i + x(\sum_{k=0}^{n-(i+1)}a_{k+i+1}x^k) \\ &= a_i x^0 + \sum_{k=0}^{n-i-1}a_{k+i+1}x^{k+1} \\ \text{L}&\text{et }\quad m = k+1 \quad\text{ then } \\ y &= a_i x^0 + \sum_{m=1}^{n-i}a_{m+i}x^m \\ &= \sum_{m=0}^{n-i}a_{m+i}x^m \end{align} $$ Termination: The loop terminates at i=-1. So $y = \sum\limits_{k=0}^{n-(i+1)}a_{k+i+1}x^k = \sum\limits_{k=0}^{n} a_x x^k$.
d. The loop invariant proves that the conclusion is true.
2-4 Inversions Let A[1…n] be an array of n distinct numbers. If i < *j* and *A*[*i*] > A[j], then the pair (i,j) is called an inversion of A. a. List the five inversions of the array ⟨2,3,8,6,1⟩. b. What array with elements from the set {1,2,…,n} has the most inversions? How many does it have? c. What is the relationship between the running time of insertion sort and the number of inversions in the input array? Justify your answer. d. Give an algorithm that determines the number of inversions in any permutation on n elements in $\Theta(n\lg n)$ worst-case time. (Hint: Modify merge sort.)
Answer
a. (1,5), (2,5), (3,4), (3,5), (4,5)
b. The array in reverse sorted order has the most inversions $\sum\limits_{i=1}^{n-1}=\frac{n(n-1)}{2}$.
c. The running time of insertion sort increases when the number of inversions increases. Because when the number of inversions increases, there are more steps to swap two element.
d. If an array consists of two sorted subarrays, we can count the number of inversions when two sorted subarrays are being merged. Let i and j be the index of two subarrays L and R in merging progress. When putting an element R[j] from right-hand array to the merged array, there is no more pair of inversions for R[j] because we are just looking for another number less than this number but the right-hand array R is sorted. There is no number less than R[j] in R[j…]. When putting an element L[i] from left-hand array to the merged array, we have to find that how many numbers less than L[j]. The desired number cannot be in subarray L because it’s sorted. No element in L[i…] is less than L[i]. So the desired element can only be in R. So the number of pairs of inversions is equal to the number of elements, which are in R, less than L[i]. The time when we put an element from left-hand array is when the element L[i] is greater than R[j]. So the number of elements, which is in R, less than L[i] is the number of elements that R have already put its elements to the merged array, which is j-1. So the number of pairs of inversions for L[i] is equal to j-1. And we can continue subdividing the problem into smaller subproblems and count the sum of inversions.
MERGE-SORT-COUNT-INVERSIONS(A, p, r)
if p < r
q = ⌊(p + r) / 2)⌋
left = MERGE-SORT-COUNT-INVERSIONS(A, p, q)
right = MERGE-SORT-COUNT-INVERSIONS(A, q + 1, r)
inversions = MERGE-COUNT-INVERSIONS(A, p, q, r) + left + right
return inversions
return 0
MERGE-COUNT-INVERSIONS(A, p, q, r)
n1 = q - p + 1
n2 = r - q
let L[1...n1+1] and R[1...n2+1] be new arrays
for i = 1 to n1
L[i] = A[p+i-1]
for j = 1 to n2
R[j] = A[q+j]
L[n1+1] = ∞
R[n2+1] = ∞
i = 1
j = 1
inversions = 0
for k = p to r
if L[i] <= R[j]
inversions = inversions + j - 1
A[k] = L[i]
i = i + 1
else
A[k] = R[j]
j = j + 1
return inversions
intmerge_sort(int[],int,int);intmerge(int[],int,int,int);intmerge_sort(int A[],int p,int r){if(p < r-1){int q =(p+r)/2;int left =merge_sort(A, p, q);int right =merge_sort(A, q, r);int inversions =merge(A, p, q, r)+ left + right;return inversions;}return0;}intmerge(int A[],int p,int q,int r){int n1 = q - p;int n2 = r - q;int L[n1+1], R[n2+1];for(int i=0; i<n1; i++)
L[i]= A[p+i];for(int j=0; j<n2; j++)
R[j]= A[q+j];
L[n1]= INT32_MAX;
R[n2]= INT32_MAX;int inversions =0;int i =0, j =0;for(int k = p; k < r; k++){if(L[i]<= R[j]){
inversions += j;
A[k]= L[i];
i++;}else{
A[k]= R[j];
j++;}}return inversions;}
Another Solution: modify the pseudocode (Line 24-31)
for k = p to r
if L[i] <= R[j]
A[k] = L[i]
i = i + 1
else
inversions = inversions + n1 - i + 1
A[k] = R[j]
j = j + 1
3. Growth of Functions
3.1 Asymptotic Notation
Θ-notation
The definition of Θ-notation: For a given function $g(n)$, we denote by $\Theta(g(n))$ the set of functions $$ \begin{align} \Theta(g(n)) = \lbrace f(n):\ {} & \text{there exist positive constant }c_1,c_2\text{, and }n_0\text{ such that } \\ & 0 \leqslant c_1 g(n) \leqslant f(n) \leqslant c_2 g(n) \text{ for all } n \geqslant n_0 \rbrace. \end{align} $$ $\Theta(g(n))$ is a set, so we could write $f(n) \in \Theta(g(n))$. However, we will usually write $f(n)=\Theta(g(n))$ to express the same notation. We say that $g(n)$ is an asymptotically tight bound for $f(n)$. The definition of $\Theta(g(n))$ requires that every member $f(n) \in \Theta(g(n))$ be asymptotically nonnegative, that is, that $f(n)$ be nonnegative whenever n is sufficiently large. (An asymptotically positive function is one that is positive for all sufficiently large n.) Consequently, the function $g(n)$ itself must be asymptotically nonnegative, or else the set $\Theta(g(n))$ is empty.
In Chapter 2, we introduced an informal notion of Θ-notation that amounted to throwing away lower-order terms and ignoring the leading coefficient of the highest-order term. Now take $\frac{1}{2}n^2-3n=\Theta(n^2)$ as example to justify this intuition. To do so, we must determine positive constants $c_1,c_2$ and $n_0$ such that $$ c_1 n^2 \leqslant \frac{1}{2}n^2-3n \leqslant c_2 n^2 $$ For all $n \geqslant n_0$. Dividing by $n^2$ fields $$ c_1 \leqslant \frac{1}{2} - \frac{3}{n} \leqslant c_2 $$ By choosing $c_1=\frac{1}{14}, c_2=\frac{1}{2}, n_0=7$, we can verify that $\frac{1}{2}n^2-3n = \Theta(n^2)$.
We can also use the formal definition to verify that $6n^3 \neq \Theta(n^2)$. $$ 6n^3 \leqslant c_2 n^2 $$ Dividing by $n^2$ yields $n \leqslant \frac{c_2}{6}$. it cannot possibly hold for arbitrarily large n, since $c_2$ is constant.
For any polynomial $p(n)=\sum\limits_{i=0}^d a_i n^i$, where the $a_i$ are constants and $a_d > 0$, we have $p(n) = \Theta(n^d)$.
We shall often use the notation $\Theta(1)$ to mean either a constant or a constant function with respect to some variable.
O-notation
The Θ-notation asymptotically bounds a function from above and below. When we have only an asymptotic upper bound, we use O-notation (pronounced big-oh or sometimes oh).
For a given function $g(n)$, we denote by $O(g(n))$ the set of functions $$ \begin{align} O(g(n)) = \lbrace f(n):\ {} & \text{there exist positive constant }c\text{, and }n_0\text{ such that } \\ & 0 \leqslant f(n) \leqslant cg(n) \text{ for all } n \geqslant n_0 \rbrace. \end{align} $$
Note that $f(n)=\Theta(g(n))$ implies $f(n)=O(g(n))$, since Θ-notation is a stronger notation than O-notation. Written set-theoretically, we have $\Theta(g(n)) \subseteq O(g(n))$.
What may be surprising is that when $a>0$, any linear function $an+b$ is in $O(n^2)$, which is easily verified by taking $c=a+|b|$ and $n_0=\max(1,-\frac{b}{a})$.
Using O-notation, we can often describe the running time of an algorithm merely by inspecting the algorithm’s overall structure. For example, the doubly nested loop structure of the insertion sort algorithm from Chapter 2 immediately yields an $O(n^2)$ upper bound on the worst-case running time: the cost of each iteration of the inner loop is bounded from above by $O(1)$ (constant), the indices i and j are both at most n, and the inner loop is executed at most once for each of the $n^2$ pairs of values for i and j.
The $\Theta(n^2)$ bound on the worst-case running time of insertion sort, however, does not imply a $\Theta(n^2)$ bound on the running time of insertion sort on every input. For example, when the input is already sorted, insertion sort runs in $\Theta(n)$ time. The $O(n^2)$ bound on worst-case running time of insertion sort also applies to its running time on every input. the actual running time varies, depending on the particular input of size n. We mean that the worst-case running time is $O(n^2)$.
Ω-notation
Ω-notation (pronounced big-omega or sometimes omega) provides an asymptotic lower bound.
For a given function $g(n)$, we denote by $\Omega(g(n))$ the set of functions $$ \begin{align} \Omega(g(n)) = \lbrace f(n):\ {} & \text{there exist positive constant }c\text{, and }n_0\text{ such that } \\ & 0 \leqslant cg(n) \leqslant f(n) \text{ for all } n \geqslant n_0 \rbrace. \end{align} $$
Theorem 3.1 For any two functions $f(n)$ and $g(n)$, we have $f(n) = \Theta(g(n))$ if and only if $f(n) = O(g(n))$ and $f(n) = \Omega(g(n))$.
When we say that the running time (no modifier) of an algorithm is $\Omega(g(n))$, we mean that no matter what particular input of size n is chosen for each value of n, the running time on that input is at least a constant c times $g(n)$. For example, the best-case running time of insertion sort is $\Omega(n)$, which implies that the running time of insertion sort is $\Omega(n)$.
The running time of insertion sort therefore belongs to both $\Omega(n)$ and $O(n^2)$. The running time of insertion sort is not $\Omega(n^2)$, since there exists an input for which insertion sort runs in $\Theta(n)$ time (e.g. when the input is already sorted). However, it’s not contradictory to say that the worst-case running time of insertion sort is $\Omega(n^2)$, since there exists an input that causes the algorithm to take $\Omega(n^2)$ time.
o-notation
The asymptotic upper bound provided by O-notation may or may not be asymptotically tight. The bound $2n^2=O(n^2)$ is asymptotically tight, but the bound $2n=O(n^2)$ is not.
We use o-notation (pronounced little-oh) to denote an upper bound that is not asymptotically tight. We formally define $o(g(n))$ as the set $$ \begin{align} o(g(n)) = \lbrace f(n):\ {} & \text{for any positive constant } c > 0 \text{, there exists a constant } n_0 > 0 \\ & \text{such that } 0 \leqslant f(n) \leqslant cg(n) \text{ for all } n \geqslant n_0 \rbrace. \end{align} $$ For example, $2n=o(n^2)$, but $2n^2 \neq o(n^2)$.
Intuitively, in o-notation, the function $f(n)$ becomes insignificant relative to $g(n)$ as n approaches infinity; that is, $$ \lim_{n \to \infty} \frac{f(n)}{g(n)} = 0 \tag{3.1} $$
ω-notation
By analogy, ω-notation is to Ω-notation as o-notation is to O-notation. We use ω-notation (pronounced little-omega) to denote a lower bound that is not asymptotically tight. $$ \begin{align} \omega(g(n)) = \lbrace f(n):\ {} & \text{for any positive constant } c > 0 \text{, there exists a constant } n_0 > 0 \\ & \text{such that } 0 \leqslant cg(n) \leqslant f(n) \text{ for all } n \geqslant n_0 \rbrace. \end{align} $$ For example, $\frac{n^2}{2}=\omega(n)$, but $\frac{n^2}{2} \neq \omega(n^2)$.
The relation $f(n)=\omega(g(n))$ implies that $$ \lim_{n \to \infty} \frac{f(n)}{g(n)} = \infty $$ if the limit exists. That is, $f(n)$ becomes arbitrarily large relative to $g(n)$ as n approaches infinity.
Comparing Functions
Many of the relational properties of real numbers apply to asymptotic comparisons as well. For the following, assume that $f(n)$ and $g(n)$ are asymptotically positive. Transitivity:
$f(n)=\Theta(g(n))$ and $g(n)=\Theta(h(n))$ imply $f(n)=\Theta(h(n))$
$f(n)=O(g(n))$ and $g(n)=O(h(n))$ imply $f(n)=O(h(n))$
$f(n)=\Omega(g(n))$ and $g(n)=\Omega(h(n))$ imply $f(n)=\Omega(h(n))$
$f(n)=o(g(n))$ and $g(n)=o(h(n))$ imply $f(n)=o(h(n))$
$f(n)=\omega(g(n))$ and $g(n)=\omega(h(n))$ imply $f(n)=\omega(h(n))$
Reflexivity:
$f(n)=\Theta(f(n))$
$f(n)=O(f(n))$
$f(n)=\Omega(f(n))$
Symmetry:
$f(n)=\Theta(g(n))$ if and only if $g(n)=\Theta(f(n))$
Transpose Symmetry:
$f(n)=O(g(n))$ if and only if $g(n)=\Omega(f(n))$
$f(n)=o(g(n))$ if and only if $g(n)=\omega(f(n))$
Because these properties hold for asymptotic notations, we can draw an analogy between the asymptotic comparison of two functions $f$ and $g$ and the comparison of two real numbers a and b:
$f(n)=O(g(n))$ is like $a \leqslant b$.
$f(n)=\Omega(g(n))$ is like $a \geqslant b$.
$f(n)=\Theta(g(n))$ is like $a = b$.
$f(n)=o(g(n))$ is like $a < b$.
$f(n)=\omega(g(n))$ is like $a > b$.
We say that $f(n)$ is asymptotically smaller than $g(n)$ if $f(n)=o(g(n))$, and $f(n)$ is asymptotically larger than $g(n)$ if $f(n)=\omega(g(n))$.
Exercises
3.1-1 Let $f(n)$ and $g(n)$ be asymptotically nonnegative functions. Using the basic definition of Θ-notation, prove that $\max(f(n),g(n)) = Θ(f(n)+g(n))$.
Answer We know there exists $n_1,n_2$ that $f(n) \geqslant 0$ for $n>n_1$ and $f(n) \geqslant 0$ for $n>n_2$. Let $c_1=\frac{1}{2},c_2=1,n_0=\max(n_1,n_2)$, then when $n>n_0$, we have $$ 0 \leqslant \frac{f(n)+g(n)}{2} \leqslant \max(f(n),g(n)) \leqslant f(n)+g(n) $$
3.1-2 Show that for any real constants a and b, where $b>0$, $$ (n+a)^b=\Theta(n^b) \tag{3.2} $$
Answer $n+a \leqslant n+|a|$, so when $n > |a|$, we have $n+a \leqslant n + |a| < n+n = 2n$. $n+a \geqslant n-|a|$, so when $|a| < \frac{n}{2}$, we have $n+a \geqslant n-|a| > \frac{n}{2}$. Therefore, when $n > 2|a|$, we have $\frac{n}{2} < n+a < 2n$. Because $b>0$, we have $(\frac{n}{2})^b < (n+a)^b < (2n)^b$ when $n>n_0=2|a|$. Therefore, $(n+a)^b=\Theta(n^b)$.
3.1-3 Explain why the statement, “The running time of algorithm A is at least $O(n^2)$,” is meaningless.
Answer $O(n^2)$ tells an upper bound, however the phrase “at least” tells a lower bound.
3.1-4 Is $2^{n+1} = O(2^n)$? Is $2^{2n}=O(2^n)$?
Answer $2^{n+1} = 2 \cdot 2^n$, which is a constant times $2^n$. So $2^{n+1} = O(2^n)$. $2^{2n} = 2^n \times 2^n$. It’s impossible to find a constant c to make $0 < 2^n \times 2^n < c \cdot 2^n$. So $2^{2n} \neq O(2^n)$.
3.1-5 Prove Theorem 3.1. For any two functions $f(n)$ and $g(n)$, we have $f(n) = \Theta(g(n))$ if and only if $f(n) = O(g(n))$ and $f(n) = \Omega(g(n))$.
Answer If $f(n) = \Theta(g(n))$, then there exist $c_1,c_2$ and $n_0$, such that $0 \leqslant c_1 g(n) \leqslant f(n) \leqslant c_2 g(n)$ when $n > n_0$. Then there exists $c=c_1$, such that $0 \leqslant cg(n) \leqslant f(n)$ for all $n>n_0$. So $f(n)=\Omega(g(n))$. There exists $c=c_2$, such that $0 \leqslant f(n) \leqslant cg(n)$ for all $n>n_0$. So $f(n)=O(g(n))$. So we have proved that $f(n) = O(g(n))$ and $f(n) = \Omega(g(n))$ if $f(n) = \Theta(g(n))$.
If $f(n)=\Omega(g(n))$, then there exists $c=c_3,n_1$, such that $0 \leqslant cg(n) \leqslant f(n)$ for all $n>n_1$. If $f(n)=O(g(n))$, then there exists $c=c_4,n_2$, such that $0 \leqslant f(n) \leqslant cg(n)$ for all $n>n_2$. Then there must exist $c_3,c_4,n_3=\max(n_1,n_2)$, such that $0 \leqslant c_3 g(n) \leqslant f(n) \leqslant c_4 g(n)$ for all $n>n_3$.
In summary, For any two functions $f(n)$ and $g(n)$, we have $f(n) = \Theta(g(n))$ if and only if $f(n) = O(g(n))$ and $f(n) = \Omega(g(n))$.
3.1-6 Prove that the running time of an algorithm is $\Theta(g(n))$ if and only if its worst-case running time is $O(g(n))$ and its best-case running time is $\Omega(g(n))$.
Answer If $T_b(n)$ is the best-case running time, then $0 \leqslant c_1 g(n) \leqslant T_b(n)$ for all $n>n_b$. If $T_w(n)$ is the worst-case running time, then $0 \leqslant T_w(n) \leqslant c_2 g(n)$ for all $n>n_w$. We know $T_b(n) \leqslant f(n) \leqslant T_w(n)$, then $0 \leqslant c_1 g(n) \leqslant T_b(n) \leqslant f(n) \leqslant T_w(n) \leqslant c_2 g(n)$ for all $n>\max(n_b,n_w)$.
3.1-7 Prove that $o(g(n)) \cap \omega(g(n))$ is the empty set.
Answer $f(n)=o(g(n))$ means that for all $c_1>0$, there exists $n_0$ such that $0 \leqslant f(n) < c_1 g(n)$ for all $n>n_0$. $f(n)=\omega(g(n))$ means that for all $c_2>0$, there exists $n_0$ such that $0 \leqslant c_2 g(n) < f(n)$ for all $n>n_0$. $o(g(n)) \cap \omega(g(n))$ means that for all $c_1>0,c_2>0$, there exists $0 \leqslant c_2 g(n) < f(n) < c_1 g(n)$ for all $n>n_0$. However, when $c_1=c_2$, there is no $n_0$ such that $c_1 g(n) < f(n) < c_1 g(n)$ for all $n>n_0$. So the function $f(n)$ does not exist, i.e. $o(g(n)) \cap \omega(g(n))$ is the empty set.
3.1-8 We can extend our notation to the case of two parameters n and m that can go to infinity independently at different rates. For a given function $g(n,m)$, we denote by $O(g(n,m))$ the set of functions $$ \begin{align} O(g(n,m)) = \lbrace f(n,m):\ {} & \text{there exist positive constants } c, n_0 \text{ and } m_0 \\ & \text{such that } 0 \leqslant f(n,m) \leqslant cg(n,m) \\ & \text{for all } n \geqslant n_0 \text{ or } m \geqslant m_0 \rbrace. \end{align} $$ Give corresponding definitions for $\Omega(g(n,m)$ and $\Theta(g(n,m))$.
Answer $$ \begin{align} \Omega(g(n,m)) = \lbrace f(n,m):\ {} & \text{there exist positive constants } c, n_0 \text{ and } m_0 \\ & \text{such that } 0 \leqslant cg(n,m) \leqslant f(n,m) \\ & \text{for all } n \geqslant n_0 \text{ or } m \geqslant m_0 \rbrace \\ \\ \Theta(g(n,m)) = \lbrace f(n,m):\ {} & \text{there exist positive constants } c_1, c_2, n_0 \text{ and } m_0 \\ & \text{such that } 0 \leqslant c_1 g(n,m) \leqslant f(n,m) \leqslant c_2 g(n,m) \\ & \text{for all } n \geqslant n_0 \text{ or } m \geqslant m_0 \rbrace \end{align} $$
3.2 Standard Notations and Common Functions
We have already learned them in mathematics. So I just give the translation of the terminologies and skip the exercises.
English
中文
monotonicity
单调性
monotonically increasing
单调递增
monotonically decreasing
单调递减
strictly increasing
严格递增
strictly decreasing
严格递减
floor
向下取整
ceiling
向上取整
modular arithmetic
模运算
remainder / residue
余数
quotient
商
be equivalent to
等价于
polynomial
多项式
polynomially bounded
多项式有界
exponential
指数
polylogarithmically bounded
多对数有界
factorial
阶乘
functional iteration
多重函数
the iterated logarithm function
多重对数函数
Fibonacci numbers
斐波那契数
golden ratio
黄金分割率
Problem
3-1 Asymptotic behavior of polynomials Let $p(n)=\sum\limits_{i=0}^d a_i n^i$, where $a_d>0$, be a degree-d polynomial in n, and let k be a constant. Use the definitions of the asymptotic notations to prove the following properties. a. If $k \geqslant d$, then $p(n)=O(n^k)$. b. If $k \leqslant d$, then $p(n)=\Omega(n^k)$. c. If $k = d$, then $p(n)=\Theta(n^k)$. d. If $k > d$, then $p(n)=o(n^k)$. e. If $k < d$, then $p(n)=\omega(n^k)$.
Answer
a. To find $$ p(n)=\sum\limits_{i=0}^d a_i n^i=a_d n^d + a_{d-1}n^{d-1} + \cdots + a_1 n + a_0 \leqslant cn^d$$ Divide by $n^d$ $$ a_d + \frac{a_{d-1}}{n} + \frac{a_{d-2}}{n^2} + \cdots + \frac{a_0}{n^d} \leqslant c$$ When $n=\max(da_{d-1}, d\sqrt{a_{d-2}},\cdots,d\sqrt[d]{a_0})$, we have $\frac{a_{d-1}}{n} + \frac{a_{d-2}}{n^2} + \cdots + \frac{a_0}{n^d} < 1$. Then when $c > a_d + 1$, we have $p(n) \leqslant cn^d$ for all $n>n_0$. If $k \geqslant d$, then $p(n) \leqslant cn^d \leqslant cn^k$. Thus $p(n)=O(n^k)$.
We can easily prove problem b to e easily by this method.
3-2 Relative asymptotic growths Indicate, for each pair of expressions (A,B) in the table below, whether A is O, o, Ω, ω, or Θ of B. Assume that k≥1, ϵ>0, and c>1 are constants. Your answer should be in the form of the table with “yes” or “no” written in each box.
Answer
A
B
O
o
Ω
ω
Θ
$\lg^k n$
$n^\epsilon$
yes
yes
no
no
no
$n^k$
$c^n$
yes
yes
no
no
no
$\sqrt{n}$
$n^{\sin{n}}$
no
no
no
no
no
$2^n$
$2^\frac{n}{2}$
no
no
yes
yes
no
$n^{\lg{c}}$
$c^{\lg{n}}$
yes
no
yes
no
yes
$\lg(n!)$
$\lg(n^n)$
yes
no
yes
no
yes
3-3 Ordering by asymptotic growth rates a. Rank the following functions by order of growth; that is, find an arrangement $g_1, g_2, \ldots , g_{30}$ of the functions $g_1 = \Omega(g_2), g_2 = \Omega(g_3), \ldots, g_{29} = \Omega(g_{30})$. Partition your list into equivalence classes such that functions $f(n)$ and $g(n)$ are in the same class if and only if $f(n) = \Theta(g(n))$.
b. Give an example of a single nonnegative function $f(n)$ such that for all functions $g_i(n)$ in part (a), $f(n)$ is neither $O(g_i(n))$ nor $\Omega(g_i(n))$.
b. $$ f(n) = \begin{cases} 2^{2^{n + 2}} & \text{if $n$ is even}, \\ 0 & \text{if $n$ is odd}. \end{cases} $$ for all functions $g_i(n)$ in part (a), $f(n)$ is neither $O(g_i(n))$ nor $\Omega(g_i(n))$.
3-4 Asymptotic notation properties Let $f(n)$ and $g(n)$ be asymptotically positive functions. Prove or disprove each of the following conjectures. a. $f(n) = O(g(n))$ implies $g(n) = O(f(n))$. b. $f(n) + g(n) = \Theta(\min(f(n), g(n)))$. c. $f(n) = O(g(n))$ implies $\lg(f(n)) = O(\lg(g(n)))$, where $\lg(g(n)) \geqslant 1$ and $f(n) \geqslant 1$ for all sufficiently large n. d. $f(n) = O(g(n))$ implies $2^{f(n)} = O(2^{g(n)})$. e. $f(n) = O((f(n))^2)$. f. $f(n) = O(g(n))$ implies $g(n) = \Omega(f(n))$. g. $f(n) = \Theta(f(\frac{n}{2}))$. h. $f(n) + o(f(n)) = \Theta(f(n))$.
Answer
a. The conjecture is false because $n=O(n^2)$ but $n^2 \neq O(n)$.
b. The conjecture is false because for $n^2 + n$, $\Theta(\min(n^2,n))=\Theta(n)$ but $n^2 + n \neq \Theta(n)$.
c. The conjecture is true. $f(n) = O(g(n))$ means that there exist $c>0,n_0$, such that $0 \leqslant f(n) \leqslant cg(n)$ for all $n>n_0$. Because $f(n)>1$ and $\lg(g(n))>1$, we have $0 \leqslant \lg f(n) \leqslant \lg(cg(n)) = \lg c + \lg g(n)$. Let $\begin{gather} d=\cfrac{\lg c + \lg g(n)}{\lg g(n)} = \cfrac{\lg c}{\lg g(n)} + 1 \leqslant \lg c + 1 \end{gather}$. Then $0 \leqslant \lg f(n) \leqslant d\lg g(n) = \lg c + \lg g(n)$ for all sufficiently large n. Therefore $\lg(f(n)) = O(\lg(g(n)))$.
d. The conjecture is false because $2n=O(n)$ but $2^{2n}=4^n \neq O(2^n)$.
e. The conjecture is false. If $f(n)>1$, it’s true that $0 \leqslant f(n) \leqslant f^2(n)$. However, if $f(n)<1$, the inequality not true.
f. The conjecture is true. For $f(n) = O(g(n))$, we know that there exist $c>0,n_0$, such that $0 \leqslant f(n) \leqslant cg(n)$ for all $n>n_0$. So when $d=\frac{1}{c}$, we have $0 \leqslant df(n) \leqslant g(n)$, which proves that $g(n) = \Omega(f(n))$.
g. The conjecture is false because if $f(n) = 4^n$, then $f(n) \neq \Theta(f(\frac{n}{2}))=\Theta(2^n)$.
h. The conjecture is true. Let $g(n)=o(f(n))$, then g(n) are all functions which $0 \leqslant g(n) \leqslant cf(n)$ for all $c>0, n>n_0$. Let $c_1=1, c_2=c+1$, then $ 0 \leqslant c_1 f(n) \leqslant f(n) + g(n) \leqslant c_2 f(n)$ for all $n>n_0$. Therefore, $f(n) + o(f(n)) = \Theta(f(n))$.
3-5 Variations on O and Ω Some authors define Ω in a slightly different way than we do; let’s use $\overset{\infty}{\Omega}$ (read “omega infinity”) for this alternative definition. We say that $f(n) = \overset{\infty}{\Omega}(g(n))$ if there exists a positive constant c such that $f(n) \geqslant cg(n) \geqslant 0$ for infinitely many integers n. a. Show that for any two functions $f(n)$ and $g(n)$ that are asymptotically nonnegative, either $f(n) = O(g(n))$ or $f(n) = \overset{\infty}{\Omega}(g(n))$ or both, whereas this is not true if we use Ω in place of $\overset{\infty}{\Omega}$. b. Describe the potential advantages and disadvantages of using $\overset{\infty}{\Omega}$ instead of Ω to characterize the running times of programs.
Some authors also define O in a slightly different manner; let’s use O’ for the alternative definition. We say that $f(n) = O’(g(n))$ if and only if $|f(n)| = O(g(n))$. c. What happens to each direction of the “if and only if” in Theorem 3.1 if we substitute O’ for O but we still use Ω?
Some authors define $\tilde O$ (read “soft-oh”) to mean O with logarithmic factors ignored: $$ \begin{align} \tilde{O}(g(n)) = \lbrace f(n): & \text{ there exist positive constants } c, k, \text{ and } n_0 \text{ such that } \\ & 0 \leqslant f(n) \leqslant cg(n)\lg^{k}(n) \text{ for all } n \ge n_0. \rbrace \end{align} $$ d. Define $\tilde\Omega$ and $\tilde\Theta$ in a similar manner. Prove the corresponding analog to Theorem 3.1.
Answer
a. For $f(n)=\Omega(g(n))$, there exists c and n, such that $0 \leqslant cg(n) \leqslant f(n)$ for all $n > n_0$. Obviously there are infinitely many integers n that satisfy the condition. However, for $f(n)=\overset{\infty}{\Omega}(g(n))$, when $n > n_0$ the inequality $0 \leqslant cg(n) \leqslant f(n)$ is not always true. For example, if the inequality is true when n is even, Then in this case there are infinitely many integers n that satisfy the condition, but it’s impossible to find an $n_0$ that make the inequality always true for all $n>n_0$. So it’s not always true if we use Ω in place of $\overset{\infty}{\Omega}$.
b. Advantage: We can use $\overset{\infty}{\Omega}$ to describe a set of more functions Disadvantage: The set is not precise, and it’s complicated to describe the functions in this set.
c. If $f(n) = \Theta(g(n))$ then $f(n) = \Omega(g(n))$ and $f(n) = O(g(n))$. So it’s true that $|f(n)| = O(g(n))$, i.e. $f(n) = O’(g(n))$. However, if $f(n) = O’(g(n))$, the function $f(n)$ may not be nonnegative. So $f(n) = O(g(n))$ may not be true. Therefore, $f(n) = \Theta(g(n))$ may not be true.
d.
$$ \begin{align} \tilde\Omega(g(n)) = \lbrace f(n): & \text{ there exist positive constants } c, k, \text{ and } n_0 \text{ such that } \\ & 0 \leqslant cg(n)\lg^{k}(n) \leqslant f(n) \text{ for all } n \ge n_0. \rbrace \\ \\ \tilde\Theta(g(n)) = \lbrace f(n): & \text{ there exist positive constants } c_1,c_2,k_1,k_2, \text{ and } n_0 \text{ such that } \\ & 0 \leqslant c_1 g(n)\lg^{k_1}(n) \leqslant f(n) \leqslant c_2 g(n)\lg^{k_2}(n) \text{ for all } n \ge n_0. \rbrace \end{align} $$ So $f(n) = \tilde\Theta(n)$ if and only if $f(n) = \tilde{O}(g(n))$ and $f(n) == \tilde{\Omega}(g(n))$.
3-6 Iterated functions We can apply the iteration operator * used in the lg* function to any monotonically increasing function $f(n)$ over the reals. For a given constant $c \in R$ , we define the iterated function $f_c^*$ by $f_c^*(n) = \min\lbrace i \geqslant 0 : f^{(i)}(n) \leqslant c\rbrace$ which need not be well defined in all cases. In other words, the quantity $f_c^*(n)$ is the number of iterated applications of the function $f$ required to reduce its argument down to c or less. For each of the following functions $f(n)$ and constants c , give as tight a bound as possible on $f_c^*(n)$.
Answer
$f(n)$
c
$f_c^*(n)$
$n-1$
0
$\Theta(n)$
$\lg n$
1
$\Theta(\lg^*(n))$
$\frac{n}{2}$
1
$\Theta(\lg n)$
$\frac{n}{2}$
2
$\Theta(\lg n)$
$\sqrt{n}$
2
$\Theta(\lg\lg n)$
$\sqrt{n}$
1
$n^{\frac{1}{3}}$
2
$\Theta(\log_3\lg n)$
$\frac{n}{\lg n}$
2
$\omega(\lg\lg n), o(\lg n)$
4. Divide-and-Conquer
4.1 The maximum-subarray problem
Maximum subarray: A nonempty, contiguous subarray of A whose values have the largest sum. Note that there may be more than one maximum subarray of an array. So we will usually say “a” maximum subarray instead of the maximum subarray.
The maximum-subarray problem is interesting only when the array contains some negative numbers. If all the array entries are positive, then the entire array would give the greatest sum. For example, there is an array A: $$ \langle \overset{1}{\boxed{13}}, \overset{2}{\boxed{-3}}, \overset{3}{\boxed{-25}}, \overset{4}{\boxed{20}}, \overset{5}{\boxed{-3}}, \overset{6}{\boxed{-16}}, \overset{7}{\boxed{-23}}, \overset{8}{\boxed{18}}, \overset{9}{\boxed{20}}, \overset{10}{\boxed{-7}}, \overset{11}{\boxed{12}}, \overset{12}{\boxed{-5}}, \overset{13}{\boxed{-22}}, \overset{14}{\boxed{15}}, \overset{15}{\boxed{-4}}, \overset{16}{\boxed{7}} \rangle $$ The maximum subarray of A[1…16] is A[8…11], with the sum 43.
Brute-force solution: Try every possible case. However, it takes $(^n_2)=\Omega(n^2)$ time. If you are interested in the pseudocode of brute-force solution, you can find it in exercise 4.1-2.
A solution using divide-and-conquer Divide-and-conquer suggests that we divide the subarray into two subarrays of as equal size as possible. After dividing, we have two subarray A[low…mid] and A[mid+1…high]. And the contiguous subarray we want can only lie in one of this three place:
entirely in the subarray A[low…mid], so that $low \leqslant i \leqslant j \leqslant mid$.
entirely in the subarray A[mid+1…high], so that $mid < i \leqslant j \leqslant high$.
crossing the midpoint, so that $low \leqslant i \leqslant mid < j \leqslant high$.
If the maximum subarray is entirely in the left, we can find a midpoint of the left subarray again until the maximum subarray is crossing the midpoint.
FIND-MAX-CROSSING-SUBARRAY(A, low, mid, high)
left-sum = -∞
sum = 0
for i=mid downto low
sum = sum + A[i]
if sum > left_sum
left_sum = sum
max-left = i
right-sum = -∞
sum = 0
for j=mid+1 to high
sum = sum + A[j]
if sum > right-sum
right-sum = sum
max-right = j
return (max-left, max-right, left_sum+right_sum)
This function returns a tuple. The total number of iterations is n. So it’s a linear-time function. Then subdividing the array and find the maximum subarray:
FIND-MAXIMUM-SUBARRAY(A, low, high)
if high == low
return (low, high, A[low]) // base case: only one element
else
mid = ⌊(low+high)/2⌋
(left-low, left-high, left-sum) = FIND-MAXIMUM-SUBARRAY(A, low, mid)
(right-low, right-high, right-sum) = FIND-MAXIMUM-SUBARRAY(A, mid+1, high)
(cross-low, cross-high, cross-sum) = FIND-MAX-CROSSING-SUBARRAY(A, low, mid, high)
if left-sum >= right-sum and left-sum >= cross-sum
return (left-low, left-high, left-sum)
elseif right-sum >= left-sum and right-sum >= cross-sum
return (right-low, right-high, right-sum)
else
return (cross-low, cross-high, cross-sum)
We find three types of sum and judge whose sum is greater, the greater one is what we want. The initial call FIND-MAXIMUM-SUBARRAY(A, 1, A.length) will find a maximum subarray of A[1…n]
C version:
typedefstructsubarray_info_struct{int low;int high;int sum;} subarray;
subarray find_max_crossing_subarray(constint A[],int low,int mid,int high){// Here uses a number small enough: INT16_MIN. And assume that sizeof(int) is 4.// Don't use INT32_MIN, or overflow may occur when INT32_MIN plus a negative number.int left_sum = INT32_MIN;int sum =0;int max_left = mid;for(int i=mid; i>=low; i--){
sum += A[i];if(sum > left_sum){
left_sum = sum;
max_left = i;}}int right_sum = INT32_MIN;
sum =0;int max_right = mid;for(int j=mid+1; j<=high; j++){
sum += A[j];if(sum > right_sum){
right_sum = sum;
max_right = j;}}return subarray{max_left, max_right, left_sum + right_sum};}
subarray find_maximum_subarray(constint A[],int low,int high){if(high == low){return subarray{low, high, A[low]};}int mid =(low + high)/2;
subarray left =find_maximum_subarray(A, low, mid);
subarray right =find_maximum_subarray(A, mid+1, high);
subarray cross =find_max_crossing_subarray(A, low, mid, high);if(left.sum >= right.sum && left.sum >= cross.sum)return left;elseif(right.sum >= left.sum && right.sum >= cross.sum)return right;elsereturn cross;}
Analyzing the divide-and-conquer algorithm
In function FIND-MAXIMUM-SUBARRAY, the call of function FIND-MAX-CROSSING-SUBARRAY takes $\Theta(n)$ time. The recursive call takes $T(n)$ time. Others take $\Theta(1)$ time. Therefore, we have $$ \begin{align} T(n) &= 2T(\frac{n}{2}) + \Theta(n) + \Theta(1) \\ &= 2T(\frac{n}{2}) + \Theta(n) \end{align} $$ For base case n=1, we have $T(1)=\Theta(1)$. So we have the recurrence for the running time of FIND-MAXIMUM-SUBARRAY. $$ T(n) = \begin{align} \begin{cases} \Theta(1) & \text{if } n = 1 \\ 2T(\frac{n}{2}) + \Theta(n) & \text{if } n > 1 \end{cases} \end{align} $$ This recurrence is the same as recurrence for merge sort. So this recurrence has the solution $T(n) = \Theta(n\lg n)$.
Exercises
4.1-1 What does FIND-MAXIMUM-SUBARRAY return when all elements of A are negative?
Answer It returns a subarray with only one element which is the greatest number in the original array.
4.1-2 Write pseudocode for the brute-force method of solving the maximum-subarray problem. Your procedure should run in $\Theta(n^2)$ time.
Answer
BRUTE-FORCE-FIND-MAXIMUM-SUBARRAY(A)
sum = -∞
for i=1 to A.length
current-sum = 0
for j=i to A.length
current-sum = current-sum + A[j]
if current-sum > sum
sum = current-sum
max-left = i
max-right = j
return (max-left, max-right, sum)
4.1-3 Implement both the brute-force and recursive algorithms for the maximum-subarray problem on your own computer. What problem size $n_0$ gives the crossover point at which the recursive algorithm beats the brute-force algorithm? Then, change the base case of the recursive algorithm to use the brute-force algorithm whenever the problem size is less than $n_0$. Does that change the crossover point?
Answer You can check the code HERE The code check the actual running time for 1000 random arrays with size from 1 to 50. The test result is that when $n_0>23$ the recursive algorithm beats the brute-force algorithm. The result may vary when it runs in different computer. When I change the base case of the recursive algorithm to use the brute-force algorithm whenever the problem size is less than $n_0$, then the recursive algorithm is almost the fastest whatever $n_0$ is. Although brute-force may beat the recursive algorithm at a random $n_0$ when $n_0 \leqslant 23$ small enough.
4.1-4 Suppose we change the definition of the maximum-subarray problem to allow the result to be an empty subarray, where the sum of the values of an empty subarray is 0. How would you change any of the algorithms that do not allow empty subarrays to permit an empty subarray to be the result?
Answer Any array has an empty subarray with the sum 0. This kind of subarray is need only if there is no subarray with positive sum. So if the original initial call returns a subarray with a negative sum, return an empty subarray instead.
4.1-5 Use the following ideas to develop a nonrecursive, linear-time algorithm for the maximum-subarray problem. Start at the left end of the array, and progress toward the right, keeping track of the maximum subarray seen so far. Knowing a maximum subarray of A[1…j], extend the answer to find a maximum subarray ending at index j+1 by using the following observation: a maximum subarray of A[1…j+1] is either a maximum subarray of A[1…j] or a subarray A[i…j+1] for some $1 \leqslant i \leqslant j+1$. Determine a maximum subarray of the form A[i…j+1] in constant time based on knowing a maximum subarray ending at index j.
Answer
ITERATIVE-FIND-MAXIMUM-SUBARRAY(A)
max-sum = -∞
cur-sum = 0
cur-low = 1
for j=1 to n
if cur-sum > 0
cur-sum = cur-sum + A[j]
else
cur-sum = A[j]
cur-low = j
if cur-sum > max-sum
max-sum = cur-sum
low = cur-low
high = j
return (low, high, max-sum)
4.2 Strassen’s algorithm for matrix multiplication
If you got rusty with matrix, you can review it HERE.
The definition of matrices multiplication: $$ c_{ij} = \sum_{k=1}^n a_{ik} \cdot b_{kj} $$ For nxn matrices multiplication:
SQUARE-MATRIX-MULTIPLY(A, B)
n = A.rows
let C be a new nxn matrix
for i=1 to n
for j=1 to n
c_ij = 0
for k=1 to n
c_ij = c_ij + a_ik * b+kj
return C
The triply-nested for loops runs exactly n iterations and others take constant time, so this function takes $\Theta(n^3)$ time.
Strassen’s method
Divide the input matrices A and B and output matrix C into $\frac{n}{2} \times \frac{n}{2}$ submatrices. This step takes $\Theta(1)$ time by index calculation, just as in SQUARE-MATRIX-MULTIPLY-RECURSIVE.
Create 10 matrices $S_1,S_2,…,S_{10}$, each of which is $\frac{n}{2} \times \frac{n}{2}$ and is the sum or difference of two matrices created in step 1. We can create all 10 matrices in $\Theta(n^2)$ time.
Using the submatrices created in step 1 and the 10 matrices created in step 2, recursively compute seven matrix products $P_1,P_2,…,P_7$. Each matrix $P_i$ is $\frac{n}{2} \times \frac{n}{2}$.
Compute the desired submatrices $C_{11},C_{12},C_{21},C_{22}$ of the result matrix C by adding and subtracting various combinations of the $P_i$ matrices. We can compute all four submatrices in $\Theta(n^2)$ time.
In the recurrence, once the matrix size n gets down to 1, we perform a simple scalar multiplication. When $n>1$, steps 1, 2 and 4 take a total of $\Theta(n^2)$ time, and step 3 requires us to perform seven multiplications of $\frac{n}{2} \times \frac{n}{2}$ matrices. Hence, we obtain the following recurrence for the running time $T(n)$ of Strassen’s algorithm: $$ T(n) = \begin{align} \begin{cases} \Theta(1) & \text{if } n = 1, \\ 7T(\frac{n}{2}) + \Theta(n^2) & \text{if } n > 1. \end{cases} \end{align} \tag{4.18} $$ This recurrence has the solution $T(n)=\Theta(n^{\lg 7})$. Since lg 7 lies between 2.80 and 2.81, Strassen’s algorithm runs in $O(n^{2.81})$ time.
STRASSEN-MATRICES-MULTIPLICATION(A, B)
n = A.rows
if n == 1
return a[1, 1] * b[1, 1]
let C be a new nxn matrix
A_11 = A[1...n/2][1...n/2]
A_12 = A[1...n/2][n/2 + 1...n]
A_21 = A[n/2 + 1...n][1...n/2]
A_22 = A[n/2 + 1...n][n/2 + 1...n]
B_11 = B[1..n / 2][1..n / 2]
B_12 = B[1..n / 2][n / 2 + 1..n]
B_21 = B[n / 2 + 1..n][1..n / 2]
B_22 = B[n / 2 + 1..n][n / 2 + 1..n]
let S be an array of matrices with size 10
S[1] = B_12 - B_22
S[2] = A_11 + A_12
S[3] = A_21 + A_22
S[4] = B_21 - B_11
S[5] = A_11 + A_22
S[6] = B_11 + B_22
S[7] = A_12 - A_22
S[8] = B_21 + B_22
S[9] = A_11 - A_21
S[10] = B_11 + B_12
let P be an array of matrices with size 7
P[1] = STRASSEN-MATRICES-MULTIPLICATION(A_11, S[1])
P[2] = STRASSEN-MATRICES-MULTIPLICATION(S[2], B_22)
P[3] = STRASSEN-MATRICES-MULTIPLICATION(S[3], B_11)
P[4] = STRASSEN-MATRICES-MULTIPLICATION(A_22, S[4])
P[5] = STRASSEN-MATRICES-MULTIPLICATION(S[5], S[6])
P[6] = STRASSEN-MATRICES-MULTIPLICATION(S[7], S[8])
P[7] = STRASSEN-MATRICES-MULTIPLICATION(S[9], S[10])
C[1...n/2][1...n/2] = P[5] + P[4] - P[2] + P[6]
C[1...n/2][n/2 + 1...n] = P[1] + P[2]
C[n/2 + 1...n][1...n/2] = P[3] + P[4]
C[n/2 + 1...n][n/2 + 1...n] = P[5] + P[1] - P[3] - P[7]
return C
4.3 The substitution method for solving recurrences
The substitution method for solving recurrences comprises two steps:
Guess the form of the solution.
Use mathematical induction to find the constants and show that the solution works.
For example, $$ T(n)=2T(\lfloor\frac{n}{2}\rfloor) + n. \tag{4.19} $$ We guess that the solution is $T(n)=O(n\lg n)$. Then the substitution method requires us to prove that $T(n) \leqslant cn\lg n$ for a $c>0$. Assume that this bound hold for all positive $m<n$, in particular for $m=\lfloor\frac{n}{2}\rfloor$, yielding $T(\lfloor\frac{n}{2}\rfloor) \leqslant c\lfloor\frac{n}{2}\rfloor\lg(\lfloor\frac{n}{2}\rfloor)$. Substituting into the recurrence yields $$ \begin{align} T(n) & \leqslant 2(c\lfloor\frac{n}{2}\rfloor\lg(\lfloor\frac{n}{2}\rfloor)) + n \\ & \leqslant cn\lg(\frac{n}{2}) + n \\ & = cn\lg n - cn\lg 2 + n \\ & = cn\lg n - cn + n \\ & \leqslant cn\lg n \end{align} $$ where the last step holds as long as $c \geqslant 1$.
Mathematical induction requires us to show that our solution holds for the boundary conditions. For example, if we assume that $T(1)=1$ is the only boundary condition of the recurrence. Then for $n=1$, the bound $T(n) \leqslant cn\lg n$ yields $T(1) \leqslant c1\lg 1 = 0$, which fails to hold that $T(1)=1$. However, the asymptotic notation requiring us only to prove $T(n) \leqslant cn\lg n$ for all $n > n_0$, where $n_0$ is a constant that we get to choose. So we can take this advantage to keep the boundary condition $T(1)=1$. We just need to prove the base cases when n is small like $n=2$ or $n=3$ by choosing a specific c.
Exercises
4.3-1 Show that the solution of $T(n) = T(n-1) + n$ is $O(n^2)$.
Answer We guess that $T(n) = O(n^2)$, then $T(n-1) \leqslant c(n-1)^2$. Substituting into the recurrence yields $$ \begin{align} T(n) & \leqslant c(n-1)^2 + n \\ & = cn^2 - 2cn + c + n \\ & = cn^2 + n(1-2c) + c \\ & \leqslant cn^2 \end{align} $$ where the last step holds for $c > \frac{1}{2}$.
4.3-2 Show that the solution of $T(n) = T(\lceil \frac{n}{2} \rceil) + 1$ is $O(\lg n)$.
4.3-3 We saw that the solution of $T(n) = 2T(\lfloor \frac{n}{2} \rfloor) + n$ is $O(n\lg n)$. Show that the solution of this recurrence is also $\Omega(n\lg n)$. Conclude that the solution is $\Theta(n\lg n)$.
Answer We guess that $T(n)=\Omega(n\lg n)$, then $T(\lfloor \frac{n}{2} \rfloor) \geqslant (\lfloor \frac{n}{2} \rfloor)\lg(\lfloor \frac{n}{2} \rfloor)$. Substituting into the recurrence yields $$ \begin{align} T(n) & \geqslant 2(c\lfloor\frac{n}{2}\rfloor\lg(\lfloor\frac{n}{2}\rfloor)) + n \\ & \geqslant 2(c\frac{n-1}{2}\lg(\frac{n-1}{2})) + n \\ & = c(n-1)\lg(\frac{n-1}{2}) + n \\ & = c(n-1)\lg(n-1) - c(n-1)\lg2 + n \\ & = c(n-1)\lg(n-1) - cn + n + c \\ & \geqslant c(n-1)\lg(n-1) \end{align} $$ where the last step holds for $0 < c \leqslant 1$.
Since $T(n)=\Omega(n\lg n)$ and $T(n)=O(n\lg n)$, we can infer that $T(n)=\Theta(n\lg n)$ according to Theorem 3.1.
4.3-4 Show that by making a different inductive hypothesis, we can overcome the difficulty with the boundary condition $T(1)=1$ for recurrence $\text{(4.19)}$ without adjusting the boundary conditions for the inductive proof.
Answer $$ \begin{align} T(n) & \leqslant 2(c\lfloor\frac{n}{2}\rfloor\lg(\lfloor\frac{n}{2}\rfloor)) + n \\ & \leqslant cn\lg(\frac{n}{2}) + n \\ & = cn\lg n - cn\lg 2 + n \\ & = cn\lg n + (1-c)n \\ & \leqslant cn\lg n + n \end{align} $$ where the last step holds as long as $c \geqslant 0$. Then the boundary condition is $T(1) = c1\lg1 + 1 = 1$.
4.3-5 Show that $\Theta(n\lg n)$ is the solution to the “exact” recurrence (4.3) for merge sort. $$ T(n) = \begin{align} \begin{cases} \Theta(1) & \text{if } n = 1 \\ T(\lceil\frac{n}{2}\rceil) + T(\lfloor\frac{n}{2}\rfloor) + \Theta(n) & \text{if } n > 1 \end{cases} \end{align} \tag{4.3} $$
4.3-6 Show that the solution to $T(n) = 2T(\lfloor \frac{n}{2} \rfloor + 17) + n$ is $O(n\lg n)$.
Answer We guess that $T(n) \leqslant c(n-34)\lg(n-34)$. $$ \begin{align} T(n) & \leqslant 2c(\lfloor\frac{n-34}{2}\rfloor + 17)\lg(\lfloor\frac{n-34}{2}\rfloor + 17) + n \\ & \leqslant 2c(\frac{n-34}{2}+17)\lg(\frac{n-34}{2}+17) + n \\ & = 2c(\frac{n}{2})\lg(\frac{n}{2}) + n \\ & = cn\lg(\frac{n}{2}) + n \\ & = cn\lg n - cn\lg 2 + n \\ & = cn\lg n + (1-c)n \\ & \leqslant cn\lg n \end{align} $$ where the last step holds for $c \geqslant 1$.
4.3-7 Using the master method in Section 4.5, you can show that the solution to the recurrence $T(n) = 4T(\frac{n}{3}) + n$ is $T(n) = \Theta(n^{\log_3 4})$. Show that a substitution proof with the assumption $T(n) \leqslant cn^{\log_3 4}$ fails. Then show how to subtract off a lower-order term to make the substitution proof work.
Answer TODO
4.3-8 Using the master method in Section 4.5, you can show that the solution to the recurrence $T(n) = 4T(\frac{n}{2}) + n$ is $T(n) = \Theta(n^2)$. Show that a substitution proof with the assumption $T(n) \leqslant cn^2$ fails. Then show how to subtract off a lower-order term to make the substitution proof work.
Answer TODO
4.4 The recursion-tree method for solving recurrences
In a recursion tree, each node represents the cost of a single subproblem somewhere in the set of recursive function invocations. We sum the costs within each level of the tree to obtain a set of per-level costs, and then we sum all the per-level costs to determine the total cost of all levels of the recursion.
Exercises
TODO
4.5 The master method for solving recurrences
The master method
$$ T(n) = aT(\frac{n}{b}) + f(n) \tag{4.20} $$ where $a \geqslant 1$ and $b > 1$ are constants and $f(n)$ is an asymptotically positive function.
The master theorem
Theorem 4.1 (Master theorem) Let $a \geqslant 1$ and $b > 1$ be constants, let $f(n)$ be a function, and let $T(n)$ be defined on the nonnegative integers by the recurrence $$ T(n) = aT(\frac{n}{b}) + f(n) $$ where we interpret $\frac{n}{b}$ to mean either $\lfloor\frac{n}{b}\rfloor$ or $\lceil\frac{n}{b}\rceil$. Then $T(n)$ has the following asymptotic bounds:
If $f(n) = O(n^{\log_b a-\epsilon})$ for some constant $\epsilon > 0$, then $T(n) = \Theta(n^{\log_b a})$.
If $f(n) = \Theta(n^{\log_b a})$, then $T(n) = \Theta(n^{\log_b a}\lg n)$.
If $f(n) = \Omega(n^{\log_b a+\epsilon})$ for some constant $\epsilon > 0$, and if $af(\frac{n}{b}) \leqslant cf(n)$ for some constant $c < 1$ and all sufficiently large n, then $T(n) = \Theta(f(n))$.
Note that here are $n^{(\log_b a)-\epsilon}$ or $n^{(\log_b a)+\epsilon}$, not $n^{\log_b (a-\epsilon)}$ or $n^{\log_b (a+\epsilon)}$.
Intuitively, we compare the function $f(n)$ with the function $n^{\log_b a}$. The larger of the two functions determines the solution to the recurrence.
If the function $f(n)$ is the larger, then the solution is $T(n)=\Theta(n^{\log_b a})$.
If the two functions are the same size, we multiply by a logarithmic factor ($\lg n$), and the solution is $T(n)=\Theta(n^{\log_b a}\lg n) = \Theta(f(n)\lg n))$.
If the function $n^{\log_b a}$ is the larger, then the solution is $T(n)=\Theta(f(n))$.
Note that in case 1, not only must $f(n)$ be smaller than $n^{\log_b a}$, it also must be polynomially smaller. That is, $f(n)$ must be asymptotically smaller than $n^{\log_b a}$ by a factor of $n^\epsilon$ for some constant $\epsilon > 0$.
In case 3, ont only must $f(n)$ be larger than $n^{\log_b a}$, it also must be polynomially larger and in addition satisfy the “regularity” condition that $af(\frac{n}{b}) \leqslant cf(n)$.
If these additional conditions fail, you cannot use the master method to solve the recurrence.
Using the master method
Example 1: $T(n) = 9T(\frac{n}{3}) + n$.
For this recurrence, we have $a=9,b=3,f(n)=n$, and thus we have $n^{\log_b a} = n^{\log_3 9}=\Theta(n^2)$. Since $f(n) = n = O(n^{\log_3 9-\epsilon})$, where $\epsilon = 1$, we can apply case 1 of the master theorem and conclude that the solution is $T(n) = \Theta(n^2)$.
Example 2: $T(n) = T(\frac{2n}{3}) + 1$.
For this recurrence, we have $a=1,b=\frac{3}{2},f(n)=1$, thus we have $n^{\log_b a} = n^{\log_{\frac{3}{2}} 1} = n^0 = 1$. Since $f(n) = \Theta(n^{\log_b a}) = \Theta(1)$, case 2 applies, and thus the solution to the recurrence is $T(n) = \Theta(\lg n)$.
Example 3: $T(n) = 3T(\frac{n}{4}) + n\lg n$.
We have $a=3,b=4,f(n)=n\lg n$, and $n^{\log_b a} = n^{\log_4 3} = O(n^{0.793})$. Since $f(n) = \Omega(n^{\log_4 3+\epsilon})$, where $\epsilon \approx 0.2$, case 3 applies if we can show that the regularity condition holds for $f(n)$. For sufficiently large n, we have that $af(\frac{n}{b}) = 3(\frac{n}{4})\lg\frac{n}{4} \leqslant \frac{3}{4}n\lg n = cf(n)$ for $c=\frac{3}{4}$. Consequently, by case 3, the solution to the recurrence is $T(n) = \Theta(n\lg n)$.
Example 4: $T(n) = 2T(\frac{n}{2}) + \Theta(n)$. Here we have $a=2,b=2,f(n)=\Theta(n)$, and thus $n^{\log_b a}=n^{\log_2 2}=n$. Case 2 applies, since $f(n) = \Theta(n)$, and so we have the solution $T(n) = \Theta(n\lg n)$.
Example that the master method does not apply to the recurrence: $T(n) = 2T(\frac{n}{2}) + n\lg n$.
Here we have $a=2,b=2,f(n)=n\lg n$, and thus $n^{\log_b a}=n^{\log_2 2}=n$. However, the case 3 doesn’t apply, since $f(n) = n\lg n$ is asymptotically larger than $n^{\log_b a}=n$.
Exercises
4.5-1 Use the master method to give tight asymptotic bounds for the following recurrences. a. $T(n) = 2T(\frac{n}{4} + 1)$. b. $T(n) = 2T(\frac{n}{4} + \sqrt{n})$. c. $T(n) = 2T(\frac{n}{4} + n)$. d. $T(n) = 2T(\frac{n}{4} + n^2)$.
Answer
a. We have $a=2,b=4,f(n)=1$, and thus $n^{\log_b a}=n^{\log_4 2}=\sqrt{n}$. Since $f(n)=1=O(n^{\log_4 2-\epsilon})$ where $\epsilon=\frac{1}{2}$, so we have $T(n)=\Theta(\sqrt{n})$
b. We have $a=2,b=4,f(n)=\sqrt{n}$. Since $f(n)=\sqrt{n}=\Theta(\sqrt{n})$, so we have $T(n)=\Theta(\sqrt{n}\lg n)$
c. We have $a=2,b=4,f(n)=n$. Since $f(n)=n=\Omega(n^{\log_4 2+\epsilon})$, where $\epsilon=\frac{1}{2}$. For sufficiently large n, we have that $af(\frac{n}{b})=2f(\frac{n}{4})=\frac{n}{2} \leqslant cf(n)$ where $c=\frac{1}{2}$. Consequently, the solution to the recurrence is $T(n) = \Theta(n)$.
d. We have $a=2,b=4,f(n)=n^2$. Since $f(n)=n^2=\Omega(n^{\log_4 2+\epsilon})$, where $\epsilon=\frac{3}{2}$. For sufficiently large n, we have that $af(\frac{n}{b})=2f(\frac{n}{4})=\frac{n^2}{8} \leqslant cf(n)$ where $c=\frac{1}{8}$. Consequently, the solution to the recurrence is $T(n) = \Theta(n^2)$.
4.5-2 Professor Caesar wishes to develop a matrix-multiplication algorithm that is asymptotically faster than Strassen’s algorithm. His algorithm will use the divide-and-conquer method, dividing each matrix into pieces of size $\frac{n}{4} \times \frac{n}{4}$, and the divide and combine steps together will take $\Theta(n^2)$ time. He needs to determine how many subproblems his algorithm has to create in order to beat Strassen’s algorithm. If his algorithm creates $a$ subproblems, then the recurrence for the running time $T(n)$ becomes $T(n) = aT(\frac{n}{4}) + \Theta(n^2)$. What is the largest integer value of $a$ for which Professor Caesar’s algorithm would be asymptotically faster than Strassen’s algorithm?
Answer Strassen’s algorithm runs in $\Theta(n^{\lg 7})$ time. In order to make the new algorithm faster than Strassen’s, the new one should run in $o(\lg 7)$ and $\omega(n^2)$ time, since it should be faster but impossible to be faster than $\Omega(n^2)$. For the recurrence $T(n) = aT(\frac{n}{4}) + \Theta(n^2)$, we have $b=4,f(n)=\Theta(n^2)$. Therefore, $f(n) = \Theta(n^{\lg 7}) = O(n^{\log_4 a - \epsilon})$ for some $\epsilon > 0$. In order to make $f(n) = \Theta(n^{\lg 7})$, we have $\log_4 a - \epsilon = \lg 7$. Additionally, to make $f(n)$ asymptotically smaller than $n^{\log_b a}$ by a factor $n^\epsilon$, we have $\log_4 a \leqslant \lg 7$. We know that $\log_4 49 = \lg 7$, so the largest integer $a$ is 48.
4.5-3 Use the master method to show that the solution to the binary-search recurrence $T(n) = T(\frac{n}{2}) + \Theta(1)$ is $T(n) = \Theta(\lg n)$. (See exercise 2.3-5 for a description of binary search.)
Answer We have $a=1,b=2,f(n)=\Theta(1)$, and thus $n^{\log_b a} = n^{\log_2 1} = 1$. Since $f(n) = \Theta(1) = n^{\log_b a}$, we have $T(n) = \Theta(n^{\log_b a}\lg n) = \lg n$.
4.5-4 Can the master method be applied to the recurrence $T(n) = 4T(\frac{n}{2}) + n^2\lg n$? Why or why not? Give an asymptotic upper bound for this recurrence.
Answer Here we have $a=4,b=2,f(n)=n^2\lg n$, and thus $n^{\log_b a} = n^{\log_2 4} = n^2$. However, for $f(n) = n^2\lg n = \Omega(n^2+\epsilon)$, we cannot find a $\epsilon>0$ for all sufficiently large n. So the master method cannot be applied.
We guess $T(n) \leqslant cn^2\lg^2 n$, then we have $T(\frac{n}{2}) \leqslant c(\frac{n}{2})^2\lg^2\frac{n}{2} = c\frac{1}{4}n^2(\lg n - 1)^2$. Substituting into recurrence yields $$ \begin{align} T(n) & = 4T(\frac{n}{2}) + n^2\lg n \\ & \leqslant 4c\frac{1}{4}n^2\lg^2\frac{n}{2} + n^2\lg n \\ & = cn^2\lg\frac{n}{2}(\lg n - 1) + n^2\lg n \\ & = cn^2\lg\frac{n}{2}\lg n - cn^2\lg\frac{n}{2} + n^2\lg n \\ & = cn^2(\lg n - 1)\lg n - cn^2\lg\frac{n}{2} + n^2\lg n \\ & = cn^2\lg^2 n - cn^2\lg n - cn^2\lg\frac{n}{2} + n^2\lg n \\ & = cn^2\lg^2 n + (1-c)n^2\lg n - cn^2\lg\frac{n}{2} \\ & \leqslant cn^2\lg^2 n - cn^2\lg\frac{n}{2} \quad\text{ holds when }c \leqslant 1 \\ & \leqslant cn^2\lg^2 n \end{align} $$ So $T(n) = O(cn^2\lg^2 n)$.
4.5-5 * Consider the regularity condition $af(\frac{n}{b}) \leqslant cf(n)$ for some constant $c < 1$, which is part of case 3 of the master theorem. Give an example of constants $a \geqslant 1$ and $b > 1$ and a function $f(n)$ that satisfies all the conditions in case 3 of the master theorem, except the regularity condition.
Answer $a=1,b=2,f(n)=n(2-\cos n)$.
* 4.6 Proof of the master theorem
TODO
Problem
TODO
5. Probabilistic Analysis and Randomized Algorithms
TODO
PART II: SORTING AND ORDER STATISTICS
In practice, the numbers to be sorted are rarely isolated values. Each is usually part of a collection of data called a record. Each record contains a key, which is the value to be sorted. The remainder of the record consists of satellite data, which are usually carried around with the key. In practice, when a sorting algorithm permutes the keys, it must permute the satellite data as well.
We say a sorting algorithm sorts in place if only a constant number of elements of the input array are ever stored outside the array.
A summary of the running times of the sorting algorithms
Algorithm
Worst-case running time
Average-case/expected running time
Insertion sort
$\Theta(n^2)$
$\Theta(n^2)$
Selection sort
$\Theta(n^2)$
$\Theta(n^2)$
Bubble sort
$\Theta(n^2)$
$\Theta(n^2)$
Merge sort
$\Theta(n\lg n)$
$\Theta(n\lg n)$
Heapsort
$O(n\lg n)$
–
Quicksort
$\Theta(n^2)$
$\Theta(n\lg n)$ (expected)
Counting sort
$\Theta(k + n)$
$\Theta(k + n)$
Radix sort
$\Theta(d(n + k))$
$\Theta(d(n + k))$
Bucket sort
$\Theta(n^2)$
$\Theta(n)$ (average-case)
6. Heapsort
6.1 Heaps
The (binary) heap data structure is an array object that we can view as a nearly complete binary tree. An array A that represents a heap is an object with two attributes:
A.length: which (as usual) gives the number of elements in the array
A.heap-size: which represents how many elements in the heap are stored within array A.
The root of the tree is A[1]. Given the index i of a node, we can compute the indices of its parent, left child, and right child.
If using bit shifting, the multiplication can be faster:
inlineintparent(int i){return i >>1;}inlineintleft(int i){return i <<1;}inlineintright(int i){return i <<1+1;}
There are two kinds of binary heaps:
max-heaps: the max-heap property is that for every node i other than the root, $A[\text{PARENT}(i)] \geqslant A[i]$. The largest element in a max-heap is stored at the root, and the subtree rooted at a node contains values no larger than that contained at the node itself.
min-heaps: the min-heap property is that for every node i other than the root, $A[\text{PARENT}(i)] \leqslant A[i]$. The smallest element in a min-heap is at the root.
For the heapsort algorithm, we use max-heaps. Min-heaps commonly implement priority queues.
Viewing a heap as a tree, we define the height of a node in a heap to be the number of edges on the longest simple downward path from the node to a leaf, and we define the height of the heap to be the height of its root. Since a heap of n element is based on a complete binary tree, its height is $\Theta(\lg n)$.
Exercises
6.1-1 What are the minimum and maximum numbers of elements in a heap of height h?
Answer Maximum: $2^{h+1}-1$. Minimum: $2^h$.
6.1-2 Show that an n-element heap has height $\lfloor\lg n\rfloor$.
Answer From exercise 6.1-1 we have the number n of elements in a heap of height h is between $2^h$ and $2^{h+1}-1$. The height must be integer, so an n-element heap has height $\lfloor\lg n\rfloor$.
6.1-3 Show that in any subtree of a max-heap, the root of the subtree contains the largest value occurring anywhere in that subtree.
Answer Refer to the max-heap property.
6.1-4 Where in a max-heap might the smallest element reside, assuming that all elements are distinct?
Answer In the leaves, whose indices are $\lfloor\frac{n}{2}\rfloor + k$ where k is an integer and $1 \leqslant k \leqslant n$.
6.1-5 Is an array that is in sorted order a min-heap?
Answer We don’t know which order the sorted array is in. If the sorted array is in an increasing order, then it’s a min-heap.
6.1-6 Is the sequence $\langle 23, 17, 14, 6, 13, 10, 1, 5, 7, 12 \rangle$ a max-heap?
Answer No. Because the parent of ninth element is greater than the child: $[9]=7 > [\text{PARENT}(9)=4]=6$.
6.1-7 Show that, with the array representation for storing an n-element heap, the leaves are the nodes indexed by $\lfloor\frac{n}{2}\rfloor+1, \lfloor\frac{n}{2}\rfloor+2, …, n$.
Answer Refer to exercise 6.1-4 and 6.1-1.
6.2 Maintaining the heap property
The procedure MAX-HEAPIFY assumes that the left and right child of a node are max-heaps, but the parent node might be smaller than its children. In order to maintain the max-heap property, MAX-HEAPIFY lets the value at the parent “float down” in the max-heap so that the subtree rooted at index i obeys the property.
MAX-HEAPIFY(A,i)
l = LEFT(i)
r = RIGHT(i)
if l <= A.heap-size and A[l] > A[i]
largest = l
else
largest = i
if r <= A.heap-size and A[r] > A[largest]
largest = r
if largest != i
exchange A[i] with A[largest]
MAX-HEAPIFY(A, largest)
voidmax_heapify(int A[],int i,int heap_size){
l =left(i);
r =right(i);int largest = i;if(l <= heap_size && A[l]> A[i])
largest = l;if(r <= heap_size && A[r]> A[largest])
largest = r;if(largest != i){int temp = A[i];
A[i]= A[largest];
A[largest]= temp;max_heapify(A, i, heap_size);}}
The running time of MAX-HEAPIFY on a subtree of size n rooted at a given node i is the $\Theta(1)$ time, plus the time to run MAX-HEAPIFY on a subtree rooted at one of the children of node i. The children’s subtrees each have size at most $\frac{2n}{3}$—the worst case occurs when the bottom level of the tree is exactly half full—and therefore we can describe the running time of MAX-HEAPIFY by the recurrence $$ T(n) \leqslant T(\frac{2n}{3}) + \Theta(1) $$ The solution to this recurrence is $T(n) = O(\lg n)$. Alternatively, we can characterize the running time of MAX-HEAPIFY on a node of height h as $O(h)$.
Exercises
6.2-1 Using Figure 6.2 as a model, illustrate the operation of MAX-HEAPIFY(A, 3) on the array A=⟨27,17,3,16,13,10,1,5,7,12,4,8,9,0⟩.
Answer
6.2-2 Starting with the procedure MAX-HEAPIFY, write pseudocode for the procedure MIN-HEAPIFY(A,i), which performs the corresponding manipulation on a min-heap. How does the running time of MIN-HEAPIFY compare to that of MAX-HEAPIFY?
Answer
MIN-HEAPIFY(A,i)
l = LEFT(i)
r = RIGHT(i)
min-index = i
if l <= A.heap-size and A[l] < A[i]
min-index = l
if r <= A.heap-size and A[r] < A[largest]
min-index = r
if min-index != i
exchange A[i] with A[min-index]
MIN-HEAPIFY(A, min-index)
The running time is $\Theta(\lg n)$, the same as MAX-HEAPIFY.
6.2-3 What is the effect of calling MAX-HEAPIFY(A,i) when the element A[i] is larger than its children?
Answer No effect.
6.2-4 What is the effect of calling MAX-HEAPIFY(A,i) for i > A.heap-size/2?
Answer No effect, since the check l <= A.heap-size and r <= A.heap-size fail.
6.2-5 The code for MAX-HEAPIFY is quite efficient in terms of constant factors, except possibly for the recursive call in line 12, which might cause some compilers to produce inefficient code. Write an efficient MAX-HEAPIFY that uses an iterative control construct (a loop) instead of recursion.
Answer
MAX-HEAPIFY(A,i)
while i < A.heap-size
l = LEFT(i)
r = RIGHT(i)
largest = i
if l <= A.heap-size and A[l] > A[i]
largest = l
if r <= A.heap-size and A[r] > A[largest]
largest = r
if largest != i
exchange A[i] with A[largest]
i = largest
else
break
6.2-6 Show that the worst-case running time of MAX-HEAPIFY on a heap of size n is $\Omega(\lg n)$. (Hint: For a heap with n nodes, give node values that cause MAX-HEAPIFY to be called recursively at every node on a simple path from the root down to a leaf.)
Answer The worst-case is when an element should be recursively moved down to the leaf node. Since the height of the heap is $\lfloor\lg n\rfloor$, the worst-case running time is $\Omega(\lg n)$.
6.3 Building a heap
BUILD-MAX-HEAP(A)
A.heap-size = A.length
for i = ⌊A.length/2⌋ downto 1
MAX-HEAPIFY(A,i)
Loop invariant: At the start of each iteration of the for loop of lines 3-4, each node i+1, i+2, …, n is the root of a max-heap. Initialization: Prior to the first iteration of the loop, $i = \lfloor\frac{n}{2}\rfloor$. Each node $\lfloor\frac{n}{2}\rfloor + 1, \lfloor\frac{n}{2}\rfloor + 2, …, n$ is a leaf and is thus the root of a trivial max-heap. Maintenance: To see that each iteration maintains the loop invariant, observe that the children of node i are numbered higher than i. By the loop invariant, therefore, they are both roots of max-heaps. This is precisely the condition required for the call MAX-HEAPIFY(A,i) to make node i a max-heap root. Moreover, the MAX-HEAPIFY call preserves the property that nodes i+1, i+2, …, n are all roots of max-heaps. Decrementing i in the for loop update reestablishes the loop invariant for the next iteration. Termination: At termination, i=0. By the loop invariant, each node 1,2,…,n is the root of a max-heap. In particular, node 1 is.
Each call to MAX-HEAPIFY costs $O(\lg n)$ time, and BUILD-MAX-HEAP makes $O(n)$ such calls. Thus, the running time of BUILD-MAX-HEAP is $O(n\lg n)$. However, this upper bound, though correct, is not asymptotically tight.
We know the time required by MAX-HEAPIFY when called on a node of height h is $O(h)$. The height of the root node is $\lfloor\lg n\rfloor$ and there are $\lceil\frac{n}{2^{h+1}}\rceil$ nodes in each layer. So the total cost of BUILD-MAX-HEAP is $$ \sum_{h=0}^{\lfloor\lg n\rfloor} \lceil\frac{n}{2^{h+1}}\rceil O(h) = O(n\sum_{h=0}^{\lfloor\lg n\rfloor} \frac{h}{2^h}) $$
We have the formula $$ \sum_{k=0}^\infty kx^k = \frac{x}{(1-x)^2} \tag{A.8} $$
So we evaluate the last summation by substituting $x=\frac{1}{2}$ in the formula (A.8), yielding $$ O(n\sum_{h=0}^\infty \frac{h}{2^h}) = \frac{\frac{1}{2}}{(1-\frac{1}{2})^2} = 2 $$
Thus, we can bound the running time of BUILD-MAX-HEAP as $$ O(n\sum_{h=0}^{\lfloor\lg n\rfloor} \frac{h}{2^h}) = O(n\sum_{h=0}^\infty \frac{h}{2^h}) = O(n) $$ Hence, we can build a max-heap from an unordered array in linear time.
Exercises
6.3-1 Using Figure 6.3 as a model, illustrate the operation of BUILD-MAX-HEAP on the array A = ⟨5,3,17,10,84,19,6,22,9⟩.
Answer
6.3-2 Why do we want the loop index i in line 3 of BUILD-MAX-HEAP to decrease from ⌊A.length / 2⌋ to 1 rather than increase from 1 to ⌊A.length / 2⌋?
Answer If starting from index 1, we cannot ensure that the subtrees are maximum heaps.
6.3-3 Show that there are at most $\lceil\frac{n}{2^{h+1}}\rceil$ nodes of height h in any n-element heap.
Answer Refer to exercise 6.1-4 and 6.1-1. `
6.4 The heapsort algorithm
HEAPSORT(A)
BUILD-MAX-HEAP(A)
for i = A.length downto 2
exchange A[1] with A[i]
A.heap-size = A.heap-size - 1
MAX-HEAPIFY(A,1)
The HEAPSORT procedure takes time $O(n\lg n)$, since the call to BUILD-MAX-HEAP takes time $O(n)$ and each of the n-1 calls to MAX-HEAPIFY takes time $O(\lg n)$.
Exercises
6.4-1 Using Figure 6.4 as a model, illustrate the operation of HEAPSORT on the array A = ⟨5, 13, 2, 25, 7, 17, 20, 8, 4⟩.
Answer
6.4-2 Argue the correctness of HEAPSORT using the following loop invariant: At the start of each iteration of the for loop of lines 3-6, the subarray A[1…i] is a max-heap containing the i smallest elements of A[1…n], and the subarray A[i+1…n] contains the n-i largest elements of A[1…n], sorted.
Answer Initialization: At the beginning, the subarray A[i+1…n] is empty, which is trivially sorted. Maintenance: According to the max-heap property, A[1] is the largest element in A[1…i] and less than elements in A[i+1…n]. So A[1] is the i-th smallest element and when we put it in the i position Termination: The loop terminates when i=1. After termination A[2…n] is sorted and A[i] is the smallest element, thus the array A is sorted.
6.4-3 What is the running time of HEAPSORT on an array A of length n that is already sorted in increasing order? What about decreasing order?
Answer Both are $\Theta(n\lg n)$.
6.4-4 Show that the worst-case running time of HEAPSORT is $Omega(n\lg n)$.
Answer Refer to exercise 6.4-4
6.4-5 * Show that when all elements are distinct, the best-case running time of HEAPSORT is $\Omega(n\lg n)$.
A priority queue is a data structure for maintaining a set S of elements, each with an associated value called a key. A max-priority queue supports the following operations:
INSERT(S,x) inserts the element x into the set S, which is equivalent to the operation $S = S \cup {x}$.
MAXIMUM(S) returns the element of S with the largest key.
EXTRACT0MAX(S) removes and returns the element of S with the largest key.
INCREASE-KEY(S,x,k) increases the value of element x’s key to the new value k, which is assumed to be at least as large as x’s current key value.
We can use max-priority queues to schedule jobs on a shared computer. The max-priority queue keeps track of the jobs to be performed and their relative priorities. When a job is finished or interrupted, the scheduler selects the highest-priority job from among those pending by calling EXTRACT-MAX. The scheduler can add a new job to the queue at any time by calling INSERT.
Alternatively, a min-priority queue supports the operations INSERT, MINIMUM, EXTRACT-MIN, and DECREASE-KEY. A min-priority queue can be used in an event-driven simulator.
In a given application, such as job scheduling or event-driven simulation, elements of a priority queue correspond to objects in the application. We store a handle to determine which application object corresponds to a given priority-queue element, and vice versa.
Implement the operations
HEAP-MAXIMUM(A)
return A[1]
The procedure HEAP-MAXIMUM implements the MAXIMUM operation in $\Theta(1)$ time.
HEAP-EXTRACT-MAX(A)
if A.heap-size < 1
error "heap underflow"
max = A[1]
A[1] = A[A.heap-size]
A.heap-size = A.heap-size - 1
MAX-HEAPIFY(A,1)
return max
the running time of HEAP-EXTRACT-MAX is $O(\lg n)$, since it performs only a constant amount of work on top of the $O(\lg n)$ time for MAX-HEAPIFY.
HEAP-INCREASE-KEY(A,i,key)
if key < A[i]
error "new key is smaller than current key"
A[i] = key
while i > 1 and A[PARENT(i)] < A[i]
exchange A[i] with A[PARENT(i)]
i = PARENT(i)
The running time of HEAP-INCREASE-KEY is $O(\lg n)$.
The running time of MAX-HEAP-INSERT is $O(\lg n)$.
In summary, a heap can support any priority-queue operation on a set of size n in $O(\lg n)$ time.
Exercises
6.5-1 Illustrate the operation of HEAP-EXTRACT-MAX on the heap A=⟨15,13,9,5,12,8,7,4,0,6,2,1⟩.
Answer The element A[1]=15 will be extracted and A will be ⟨13,12,9,5,6,8,7,4,0,1,2⟩.
6.5-2 Illustrate the operation of MAX-HEAP-INSERT(A, 10) on the heap A = ⟨15,13,9,5,12,8,7,4,0,6,2,1⟩.
Answer A will be ⟨15,13,10,5,12,9,7,4,0,6,2,1,8⟩.
6.5-3 Write pseudocode for the procedures HEAP-MINIMUM, HEAP-EXTRACT-MIN, HEAP-DECREASE-KEY, and MIN-HEAP-INSERT that implement a min-priority queue with a min-heap.
HEAP-MINIMUM(A)
return A[1]
HEAP-EXTRACT-MIN(A)
if A.heap-size < 1
error "heap underflow"
min = A[1]
A[1] = A[A.heap-size]
A.heap-size = A.heap-size - 1
MIN-HEAPIFY(A,1)
return min
HEAP-DECREASE-KEY(A,i,key)
if key > A[i]
error "new key is greater than current key"
A[i] = key
while i > 1 and A[PARENT(i)] > A[i]
exchange A[i] with A[PARENT(i)]
i = PARENT(i)
MIN-HEAP-INSERT(A,key)
A.heap-size = A.heap-size+1
A[heap-size] = ∞
HEAP-DECREASE-KEY(A,A.heap-size,key)
6.5-4 Why do we bother setting the key of the inserted node to -∞ in line 3 of MAX-HEAP-INSERT when the next thing we do is increase its key to the desired value?
Answer Otherwise the error “new key is smaller than current key” may occur.
6.5-5 Argue the correctness of HEAP-INCREASE-KEY using the following loop invariant:
At the start of each iteration of the while loop of lines 4-6, the subarray A[1…A.heap-size] satisfies the max-heap property, except that there may be one violation: A[i] may be larger than A[PARENT(i)].
You may assume that the subarray A[1…A.heap-size] satisfies the max-heap property at the time HEAP-INCREASE-KEY is called.
Answer Initialization: At the beginning of the while loop, the subarray A[1…A.heap-size] satisfies the max-heap property. Maintenance: In every iteration of the while loop, if A[i] is larger than A[PARENT(i)], two element will be swapped to ensure that A[PARENT(i)] > A[i]. Termination: The loop terminates when i=1 or A[PARENT(i)] > A[i]. At that time the heap satisfies the max-heap property.
6.5-6 Each exchange operation on line 5 of HEAP-INCREASE-KEY typically requires three assignments. Show how to use the idea of the inner loop of INSERTION-SORT to reduce the three assignments down to just one assignment.
Answer
HEAP-INCREASE-KEY(A, i, key)
if key < A[i]
error "new key is smaller than current key"
while i > 1 and A[PARENT(i)] < key
A[i] = A[PARENT(i)]
i = PARENT(i)
A[i] = key
6.5-7 Show how to implement a first-in, first-out queue with a priority queue. Show how to implement a stack with a priority queue. (Queues and stacks are defined in Section 10.1.)
Answer As to a stack, when we add an element, assign a key HEAP-MAXIMUM(A)+1. When taking an element, extract the minimum element. As to a stack, which is a last in, first out (LIFO) data structure, when adding an element, assign a key HEAP-MAXIMUM(A)+1. When taking an element, just call HEAP-EXTRACT-MAX.
6.5-8 The operation HEAP-DELETE(A,i) deletes the item in node i from heap A. Give an implementation of HEAP-DELETE that runs in $O(\lg n)$ time for an n-element max-heap.
Answer
HEAP-DELETE(A, i)
if A[i] > A[A.heap-size]
A[i] = A[A.heap-size]
MAX-HEAPIFY(A, i)
else
HEAP-INCREASE-KEY(A, i, A[A.heap-size])
A.heap-size = A.heap-size - 1
6.5-9 Give an $O(n\lg k)$-time algorithm to merge k sorted lists into one sorted list, where n is the total number of elements in all the input lists. (Hint: Use a min-heap for k-way merging.)
Answer Step 1: Take the first elements in every list, each element is the smallest element in each list. Put these elements in a min-heap A. In addition, we should assign a number to every element to know from which list the element is. Step 2: Extract a minimum element from the min-heap and put it into the result list. If the list which the extracted element is from is not empty, insert the minimum element from this list to the min-heap. Step 3: Repeat step 2 until the min-heap is empty.
Totally we extract n elements from those list, and each time we insert an element into the min-heap. The length of the min-heap is less than or equal to k, since we initially put k elements into the min-heap and every time we take an element, we insert one element or do nothing. So the insertion takes $O(\lg k)$ time, and we do n insertions. The total running time of this algorithm is $O(n\lg k)$.
Define a pair (list-index, element) where list-index tells which list the element is from.
MERGE-SORTED-LIST(lists)
k = lists.length
let A be a empty min-heap
// step 1
for i=1 to k
if lists[i] is not empty
A[i] = (i, lists[i].pop(1)) // list.pop(1) pops the first element in the list
BUILD-MIN-HEAP(A)
let B be a empty list
// step 2 and 3
while A is not empty
(i, element) = HEAP-EXTRACT-MIN(A) // extract the pair with minimum element
B.add(element)
if lists[i] is not empty
MIN-HEAP-INSERT(A, lists[i].pop(1))
return B
Problem
6-1 Building a heap using insertion We can build a heap by repeatedly calling MAX-HEAP-INSERT to insert the elements into the heap. Consider the following variation on the BUILD-MAX-HEAP procedure:
BUILD-MAX-HEAP'(A)
A.heap-size = 1
for i=2 to A.length
MAX-HEAP-INSERT(A,A[i])
a. Do the procedures BUILD-MAX-HEAP and BUILD-MAX-HEAP’ always create the same heap when run on the same input array? Prove that they do, or provide a counterexample. b. Show that in the worst case, BUILD-MAX-HEAP’ requires $\Theta(n\lg n)$ time to build an n-element heap.
Answer
a. A counterexample: A=⟨1,2,3⟩ BUILD-MAX-HEAP: A=⟨3,2,1⟩ BUILD-MAX-HEAP’: A=⟨3,1,2⟩
b Each insertion takes $O(\lg n)$ time, and we do n-1 insertions. So the running time is $\Theta(n\lg n)$.
6-2 Analysis of d-ary heaps A d-ary heap is like a binary heap, but (with one possible exception) non-leaf nodes have d children instead of 2 children. a. How would you represent a d-ary heap in an array? b. What is the height of a d-ary heap of n elements in terms of n and d? c. Give an efficient implementation of EXTRACT-MAX in a d-ary max-heap. Analyze its running time in terms of d and n. d. Give an efficient implementation of INSERT in a d-ary max-heap. Analyze its running time in terms of d and n. e. Give an efficient implementation of INCREASE-KEY(A,i,k), which flags an error if k < A[i], but otherwise sets A[i] = k and then updates the d-ary max-heap structure appropriately. Analyze its running time in terms of d and n.
Answer
a. Use the following functions to get the parent for the i-th element and the j-th child for the i-th element:
MAX-HEAPIFY(A,i)
largest = i
for k = 1 to d
if CHILD(i, k) ≤ A.heap-size and A[CHILD(i, k)] > A[largest]
largest = CHILD(i, k)
if largest != i
exchange A[i] with A[largest]
MAX-HEAPIFY(A, largest)
EXTRACT-MAX(A)
if A.heap-size < 1
error "heap underflow"
max = A[1]
A[1] = A[A.heap-size]
A.heap-size = A.heap-size - 1
MAX-HEAPIFY(A,1)
return max
The running time of EXTRACT-MAX is $O(d\log_d n)$.
d.
INSERT(A,key)
A.heap-size = A.heap-size + 1
A[A.heap-size] = key
i = A.heap-size
while i > 1 and A[PARENT(i)] < A[i]
exchange A[i] with A[PARENT(i)]
i = PARENT(i)
The running time of INSERT is $O(\log_d n)$.
e.
INCREASE-KEY(A,i,key)
if key < A[i]
error "new key is smaller than current key"
A[i] = key
while i > 1 and A[PARENT(i)] < A[i]
exchange A[i] with A[PARENT(i)]
i = PARENT(i)
The running time of INCREASE-KEY is $O(\log_d n)$.
6-3 Young tableaus An $m \times n$ Young tableau is an $m \times n$ matrix such that the entries of each row are in sorted order from left to right and the entries of each column are in sorted order from top to bottom. Some of the entries of a Young tableau may be ∞, which we treat as nonexistent elements. Thus, a Young tableau can be used to hold $r \leqslant mn$ finite numbers. a. Draw a $4 \times 4$ Young tableau containing the elements {9, 16, 3, 2, 4, 8, 5, 14, 12}. b. Argue that an $m \times n$ Young tableau Y is empty if $Y[1,1]=\infty$. Argue that Y is full (contains mn elements) if $Y[m,n] < \infty$. c. Give an algorithm to implement EXTRACT-MIN on a nonempty $m \times n$ Young tableau that runs in $O(m+n)$ time. Your algorithm should use a recursive subroutine that solves an $m \times n$ problem by recursively solving wither an $(m-1) \times n$ or an $m \times (n-1)$ subproblem. (Hint: Think about MAX-HEAPIFY.) Define $T(b)$, where $p=m+n$, to be the maximum running time of EXTRACT-MIN on any $m \times n$ Young tableau. Give and solve a recurrence for $T(b)$ taht yields the $O(m+n)$ time bound. d. Show how to insert a new element into a nonfull $m \times n$ Young tableau in $O(m+n)$ time. e. Using no other sorting method as a subroutine, show how to use an $n \times n$ Young tableau to sort $n^2$ numbers in $O(n^3)$ time. f. Give an $O(m+n)$-time algorithm to determine whether a given number is stored in a given $m \times n$ Young tableau.
b. For $Y[1,1]=\infty$, every element in Y is ∞. We treat ∞ as a nonexistent element, so Y is empty. For $Y[m,n]<\infty$, every element is less than Y[m,n] since every row or column is in sorted order. There is no ∞ in Y, so Y is full.
c. Let A be the target Young tableau.
A[1,1] is the smallest element in the tableau, so EXTRACT-MIN will extract this element. Inspired by MAX-HEAPIFY, we just need to replace the A[1,1] with ∞, then “max-heapify”, that is, to compare the contiguous elements on right and down position. We shift the smaller one of the contiguous elements on right or down position to ensure that every row or column of elements is sorted except the element ∞.
MAINTAIN-YOUNG-TABLEAU-PROPERTY(A,i,j)
if A[i+1,j] < A[i,j+1]
A[i,j] = A[i+1,j]
i = i + 1
else
A[i,j] = A[i,j+1]
j = j + 1
if i < A.columns or j < A.rows
MAINTAIN-YOUNG-TABLEAU-PROPERTY(A,i,j)
EXTRACT-MIN(A)
min = A[1,1]
MAINTAIN-YOUNG-TABLEAU-PROPERTY(A,1,1)
return min
If the Young tableau is full, then the worst-case occurs. In this case, the element ∞ must locate at A[m,n] when EXTRACT-MIN terminates. Every shift runs in constant time, and we do $(m+n-2)$ shifts, so the worst-case running time is $O(m+n)$. $T(p) = T(p-1) + O(1)$. The solution to this recurrence is $T(p) = O(p) = O(m+n)$.
d. If A is not full, then A[m,n] must be ∞. So just replace A[m,n] with the new element, then shift it to the correct position to maintain the property.
INSERT(A,key)
i = A.columns
j = A.rows
A[i,j] = key
while (i>1 and A[i-1,j]>A[i,j]) or (j>1 and A[i,j-1]>A[i,j])
if A[i-1,j] > A[i,j-1]
A[i-1,j] = A[i,j]
i = i - 1
else
A[i,j-1] = A[i,j]
j = j - 1
In order to maintain the property, we choose the larger one of the contiguous elements on the left or up position. If there is a ∞, replace ∞ first. If the new element is the minimum of the Young tableau, then the worst-case occurs. In this case, we do $(m+n-2)$ shifts. So the worst-case running time is $O(m+n)$.
e. The function INSERT we wrote in d runs in $O(m+n)$ time. When we do with an $n \times n$ tableau, INSERT runs in $O(n+n)=O(n)$ time. Start with an empty tableau, invoke INSERT to every number. Since there are $n^2$ numbers, each insertion takes $O(n)$ time, the total time is $n^2O(n)=O(n^3)$.
f. We can “walk” from A[m,1], go left if the current element is greater than the given number, otherwise go down.
SEARCH(A,v)
i = A.columns
j = 1
while i>=0 and j<A.rows
if A[i,j] = v
return true
if A[i,j] < v
j = j + 1
else
i = i - 1
return false
If reaching A[1,n], the worst-case occurs. In this case, we do $(m+n-2)$ walks and each cost constant time. So the algorithm runs in $O(m+n)$.
7. Quicksort
7.1 Description of quicksort
The quicksort algorithm has a worst-case running time of $\Theta(n^2)$ on an input array of n number. Despite this slow worst-case running time, quicksort is often the best practical choice for sorting because it is remarkably efficient on the average: its expected running time is $\Theta(n\lg n)$, and the constant factors hidden in the $\Theta(n\lg n)$ notation are quite small. What’s more, it works well even in virtual-memory environments.
Here is the three-step divide-and-conquer process for sorting a typical subarray A[p…r]: Divide: Partition (rearrange) the array A[p…r] into two (possibly empty) subarrays A[p…q-1] and A[q+1…r] such that each element of A[p…q-1] is less than or equal to A[q], which is, in turn, less than or equal to each element of A[q+1…r]. Compute the index q as part of this partitioning procedure. Conquer: Sort the two subarrays A[p…q-1] and A[q+1…r] by recursive calls to quicksort. Combine: Because the subarrays are already sorted, no work is needed to combine them: the entire array A[p…r] is now sorted.
QUICKSORT(A,p,r)
if p < r
q = PARTITION(A,p,r)
QUICKSORT(A,p,q-1)
QUICKSORT(A,q+1,r)
PARTITION(A,p,r)
x = A[r]
i = p - 1
for j=p to r-1
if A[j] <= x
i = i + 1
exchange A[i] with A[j]
exchange A[i+1] with A[r]
return i+1
Initial call: QUICKSORT(A, 1, A.length) or quicksort(A, 0, length_of_A) (for c version.)
Loop invariant: At the beginning of each iteration of the loop, for any array index k,
If $p \leqslant k \leqslant i$, then $A[k] \leqslant x$.
If $i+1 \leqslant k \leqslant j-1$, then $A[k] > x$.
If $k=r$, then $A[k] = x$.
The indices between j and r are not covered by any of the three cases, and the values in these entries have no particular relationship to the pivot x.
Initialization: Prior to the first iteration of the loop, $i=p-1$ and $j=p$. Because no values lie between p and i and no values lie between i+1 and j-1, the first two conditions of the loop invariant are trivially satisfied. Maintenance: When $A[j]>x$, the only action in the loop is to increment j. After j is incremented, condition 2 holds for A[j-1] and all other entries remain unchanged. When $A[j] \leqslant x$, the loop increments i, swaps A[i] and A[j], and then increments j. Because of the swap, we now have that $A[i] \leqslant x$, and condition 1 is satisfied. Similarly, we also have that $A[j-1] > x$, since the item that was swapped into A[j-1] is, by the loop invariant, greater than x. Termination: At termination, j=r. Therefore, every entry in the array is in one of the three sets described by the invariant, and we have partitioned the values in the array into three sets: those less than or equal to x, those greater than x, and a singleton set containing x.
The running time of PARTITION on the subarray A[p…r] is $\Theta(n)$, where $n=r-p+1$.
Exercises
7.1-1 Using Figure 7.1 as a model, illustrate the operation of PARTITION on the array A = ⟨13,19,9,5,12,8,7,4,21,2,6,11⟩.
7.1-2 What value of q does PARTITION return when all elements in the array A[p…r] have the same value? Modify PARTITION so that $q = \lfloor\frac{p+r}{2}\rfloor$ when all elements in the array A[p…r] have the same value.
Answer It returns r.
PARTITION(A,p,r)
x = A[r]
i = p - 1
count = 0
for j=p to r-1
if A[j] == x
count = count + 1
if A[j] <= x
i = i + 1
exchange A[i] with A[j]
exchange A[i+1] with A[r]
return i+1 - count/2
7.1-3 Give a brief argument that the running time of PARTITION on a subarray of size n is $\Theta(n)$.
Answer The for loop starts from p to r-1, so there exists $r-1-p=n-1$ iterations. each iteration runs in constant time, and other part outside the for loop runs in constant time. So the running time of PARTITION on a subarray of size n is $\Theta(n)$.
7.1-4 How would you modify QUICKSORT to sort into nonincreasing order?
Answer Modify the if-statement in PARTITION: A[j] <= x to A[j] >= x.
7.2 Performance of quicksort
The running time of quicksort depends on whether the partitioning is balanced or unbalanced.
If the partitioning is balanced, the algorithm runs asymptotically as fast as merge sort.
If the partitioning is unbalanced, it can run asymptotically as slowly as insertion sort.
Worst-case partitioning
The worst-case occurs when the partitioning routine produces one subproblem with n-1 elements and one with 0 elements. The partitioning costs $\Theta(n)$ time. Since the recursive call on an array of size 0 just returns, $T(0)=\Theta(1)$, and the recurrence for the running time is $$ \begin{align} T(n) &= T(n-1) + T(0) + \Theta(n) \\ &= T(n-1) + \Theta(n) \end{align} $$ The solution to this recurrence is $T(n) = \Theta(n^2)$.
Therefore, the worst-case running time of quicksort is no better than that of insertion sort. Moreover, the $\Theta(n^2)$ running time occurs when the input array is already completely sorted—a common situation in which insertion sort runs in $O(n)$ time.
Best-case partitioning
In the most even possible split, PARTITION produces two subproblems, each of size no more than $\frac{n}{2}$, since one is of size $\lfloor\frac{n}{2}\rfloor$ and one of size $\lfloor\frac{n}{2}\rfloor - 1$. In this case, quicksort runs much faster. The recurrence for the running time is then $$ T(n) = 2T(\frac{n}{2}) + \Theta(n) $$ The solution to this recurrence is $T(n) = \Theta(n\lg n)$.
Balanced partitioning
The average-case running time of quicksort is much closer to the best case than to the worst case.
Suppose, for example, that the partitioning algorithm always produces a 9-to-1 proportional split, which at first blush seems quite unbalanced. We then obtain the recurrence $$ T(n) = T(\frac{9n}{10}) + T(\frac{n}{10}) + cn $$ on the running time of quicksort, where we have explicitly included the constant c hidden in the $\Theta(n)$ term.
Then the recursion terminates at depth $\log_{\frac{10}{9}}n = \Theta(\lg n)$, every level costs $cn$. The total cost of quicksort is therefore $O(n\lg n)$.
Exercises
7.2-1 Use the substitution method to prove that the recurrence $T(n) = T(n-1) + \Theta(n)$ has the solution $T(n) = \Theta(n^2)$, as claimed at the beginning of Section 7.2.
Answer We guess that $T(n) \leqslant cn^2$, then $T(n-1) \leqslant c(n-1)^2$. Substituting into the recurrence yields $$ \begin{align} T(n) & = T(n-1) + c_2 n \\ & \leqslant c_1(n-1)^2 + c_2 n \\ & = c_1 n^2 - 2c_1 n + c_1 + c_2 n \\ & = c_1 n^2 + (c_2 - 2c_1)n + c_1 \\ & \leqslant c_1 n^2 \end{align} $$ where the last step holds for $c_2 < 2c_1$ and $n \geqslant \frac{c_1}{2c_1-c_2}$.
7.2-2 What is the running time of QUICKSORT when all elements of array A have the same value?
Answer $\Theta(n^2)$.
7.2-3 Show that the running time of QUICKSORT is $\Theta(n^2)$ when the array A contains distinct elements and is sorted in decreasing order.
Answer If A is sorted in decreasing order, then every call of PARTITION for a n array returns an empty subarray and a subarray of size n-1. Since the running time of PARTITION is $\Theta(n)$, we have a recurrence: $$ T(n) = T(n-1) + \Theta(n) $$ The solution to this recurrence is $T(n) = \Theta(n^2)$.
7.2-4 Banks often record transactions on an account in order of the times of the transactions, but many people like to receive their bank statements with checks listed in order by check number. People usually write checks in order by check number, and merchants usually cash them with reasonable dispatch. The problem of converting time-of-transaction ordering to check-number ordering is therefore the problem of sorting almost-sorted input. Argue that the procedure INSERTION-SORT would tend to beat the procedure QUICKSORT on this problem.
Answer The best-case of INSERTION-SORT is when the array is sorted. In this case, INSERTION-SORT runs in $O(n)$ time. If the array is almost sorted, then INSERTION-SORT just need to do few swap. For QUICKSORT, however, if the array is sorted, the worst-case occurs. In this case, QUICKSORT will run in $\Theta(n^2)$ time. If the array is almost sorted, then QUICKSORT will run slightly faster than the worst-case, which may still be slower than INSERTION-SORT. Therefore, when the array is almost sorted, INSERTION-SORT would tend to beat QUICKSORT.
7.2-5 Suppose that the splits at every level of quicksort are in the proportion 1-α to α, where $0 < \alpha \leqslant \frac{1}{2}$ is a constant. Show that the minimum depth of a leaf in the recursion tree is approximately $-\frac{\lg n}{\lg\alpha}$ and the maximum depth is approximately $-\frac{\lg n}{\lg(1-\alpha)}$. (Don’t worry about integer round-off.)
Answer $n\alpha^x \leqslant 1$ then $x \geqslant \log_\alpha \frac{1}{n}=\log_\alpha 1 - \log_\alpha n = -\frac{\lg n}{\lg\alpha}$. So the minimum depth of a leaf in the recursion tree is approximately $-\frac{\lg n}{\lg\alpha}$. Replacing α with 1-α, we can get the maximum depth is approximately $-\frac{\lg n}{\lg(1-\alpha)}$.
7.2-6 * Argue that for any constant $0 < \alpha \leqslant \frac{1}{2}$, the probability is approximately 1-2α that on a random input array, PARTITION produces a split more balanced than 1-α to α.
Answer TODO
7.3 A randomized version of quicksort
In an engineering situation, we cannot always expect the assumption we made in exploring the average-case behavior of quicksort to hold. Random sampling is sometimes used to analyze the algorithm.
RANDOMIZED-PARTITION(A,p,r)
i = RANDOM(p,r)
exchange A[r] with A[i]
return PARTITION(A,p,r)
RANDOMIZED-QUICKSORT(A,p,r)
if p < r
q = RANDOMIZED-PARTITION(A,p,r)
RANDOMIZED-QUICKSORT(A,p,q-1)
RANDOMIZED-QUICKSORT(A,q+1,r)
Exercises
7.3-1 Why do we analyze the expected running time of a randomized algorithm and not its worst-case running time?
Answer Because the array in practice is more likely randomized. The worst case rarely happens.
7.3-2 When RANDOMIZED-QUICKSORT runs, how many calls are made to the random-number generator RANDOM in the worst case? How about in the best case? Give your answer in terms of Θ-notation.
Answer
The worst case: $T(n) = T(n-1)+1 = \Theta(n)$
The best case: $T(n) = 2T(\frac{n}{2})+1 = \Theta(n)$
7.4 Analysis of quicksort
TODO
Problem
7-1 Hoare partition correctness The version of PARTITION given in this chapter is not the original partitioning algorithm. Here is the original partition algorithm, which is due to C. A. R. Hoare: HOARE-PARTITION(A,p,r)
x = A[p]
i = p - 1
j = r + 1
while TRUE
repeat
j = j - 1
until A[j] <= x
repeat
i = i + 1
until A[i] >= x
if i < j
exchange A[i] with A[j]
else return j
a. Demonstrate the operation of HOARE-PARTITION on the array A = ⟨13,19,9,5,12,8,7,4,11,2,6,21⟩, showing the values of the array and auxiliary values after each iteration of the while loop in lines 4–13.
The next three questions ask you to give a careful argument that the procedure HOARE-PARTITION is correct. Assuming that the subarray A[p…r] contains at least two elements, prove the following: b. The indices i and j are such that we never access an element of A outside the subarray A[p…r]. c. When HOARE-PARTITION terminates, it returns a value j such that $p \leqslant j < r$. d. Every element of A[p…j] is less than or equal to every element of A[j+1…r] when HOARE-PARTITION terminates.
The PARTITION procedure in Section 7.1 separates the pivot value (originally in A[r]) from the two partitions it forms. The HOARE-PARTITION procedure, on the other hand, always places the pivot value (originally in A[p]) into one of the two partitions A[p…j] and A[j+1…r]. Since $p \leqslant j < r$, this split is always nontrivial. e. Rewrite the QUICKSORT procedure to use HOARE-PARTITION.
Answer
a. $$ \begin{gather} \overset{p,i}{\boxed{13}},19,9,5,12,8,7,4,11,2,6,\overset{r,j}{\boxed{21}} \\ \overset{p,i}{\boxed{13}},19,9,5,12,8,7,4,11,2,\overset{j}{\boxed{6}},\overset{r}{21} \\ \overset{p}{6},\overset{i}{\boxed{19}},9,5,12,8,7,4,11,\overset{j}{\boxed{2}},13,\overset{r}{21} \\ \overset{p}{6},2,9,5,12,8,7,4,\overset{j}{\boxed{11}},\overset{i}{\boxed{19}},13,\overset{r}{21} \end{gather} $$ The pivot x=13. When the loop terminates, i=10 and j=9.
b. The index j starts from right and scan to left to find a number less than the pivot x. The index i starts from left and scan to right to find a number greater than the pivot x. Everytime i and j find the desired numbers, exchange two position of number, putting a number larger than the pivot x to the right and a number less than x to the left. So in the subsequent iterations, i will definitely find a number greater than x, and j will definitely find its desired number as well. When $i<j$, the loop terminates.
c. Index j starts from $j=r+1$ and will decrease in the loop. If j decrease by only 1, then $i<j$ holds because at the first iteration $A[i]=x$ so $i = p < j$. Then after the exchange, a new iteration begins, which make j decrease again. So j will be less than r after termination. Because HOARE-PARTITION terminates when $i \geqslant j$, after termination j will be greater than p. Therefore, when HOARE-PARTITION terminates, it returns a value j such that $p \leqslant j < r$.
d. When HOARE-PARTITION terminates, every element of A[p…j] greater than or equal to the pivot x will be moved to A[j+1…r], and every element of A[j+1…r] less than or equal to x will be moved to A[p…j]. So every element of A[p…j] is less than or equal to every element of A[j+1…r] when HOARE-PARTITION terminates.
e.
HOARE-QUICKSORT(A, p, r)
if p < r
q = HOARE-PARTITION(A, p, r)
HOARE-QUICKSORT(A, p, q)
HOARE-QUICKSORT(A, q + 1, r)
7-2 Quicksort with equal element values The analysis of the expected running time of randomized quicksort in Section 7.4.2 assumes that all element values are distinct. In this problem, we examine what happens when they are not. a. Suppose that all element values are equal. What would be randomized quicksort’s running time in this case? b. The PARTITION procedure returns an index q such that each element of A[p…q-1] is less than or equal to A[q] and each element of A[q+1…r] is greater than A[q]. Modify the PARTITION procedure to produce a procedure PARTITION'(A,p,r), which permutes the elements of A[p…r] and returns two indices q and t, where $p \leqslant q \leqslant t \leqslant r$, such that
all elements of A[q…t] are equal,
each element of A[p…q-1] is less than A[q], and
each element of A[t+1…r] is greater than A[q]
Like PARTITION, your PARTITION’ procedure should take $\Theta(r-p)$ time. c. Modify the RANDOMIZED-PARTITION procedure to call PARTITION’, and name the new procedure RANDOMIZED-PARTITION’. Then modify the QUICKSORT procedure to produce a procedure QUICKSORT'(A,[,r]) that calls RANDOMIZED-PARTITION’ and recurses only on partitions of elements not known to be equal to each other. d. Using QUICKSORT’, how would you adjust the analysis in Section 7.4.2 to avoid the assumption that all elements are distinct?
Answer
a. Since all elements are equal, RANDOMIZED-QUICKSORT always returns q = r. In this case the running time is $T(n) = T(n-1) + \Theta(n) = \Theta(n^2)$.
b.
PARTITION'(A, p, r)
x = A[p]
q = p
t = p
for j = p + 1 to r
if A[j] < x
temp = A[j]
A[j] = A[t + 1]
A[t + 1] = A[q]
A[q] = temp
q = q + 1
t = t + 1
else if A[j] == x
exchange A[t + 1] with A[j]
t = t + 1
return (q, t)
c.
QUICKSORT'(A, p, r)
if p < r
(q, t) = RANDOMIZED-PARTITION'(A, p, r)
QUICKSORT'(A, p, q - 1)
QUICKSORT'(A, t + 1, r)
d. We know in previous version of quicksort, every return of PARTITION is the correct and final position for pivot, since we recursively deal with A[p…q-1] and A[q+1…r] and never move A[p] again. So in the modified version, after partitioning we just need to recursively deal with A[p…q-1] and A[t+1…r], since the elements of A[q…t] are equal to the pivot, which are already in correct positions.
7-3 to 7-6: TODO
8. Sorting in Linear Time
The sorting algorithms mentioned above are comparison sorts. Any comparison sort must make $\Omega(n\lg n)$ comparisons in the worst case to sort n elements. Thus, merge sort and heapsort are asymptotically optimal, and no comparison sort exists that is faster by more than a constant factor.
8.1 Lower bounds for sorting
In a comparison sort, we use only comparisons between elements to gain order information about an input sequence $\langle a_1,a_2,…,a_n \rangle$. That is, given two elemenets $a_i$ and $a_j$, we perform one of the tests $a_i < a_j, a_i \leqslant a_j, a_i = a_j, a_i \geqslant a_j, \text{ or } a_i > a_j$ to determine their relative order.
The decision-tree model
We can view comparison sorts abstractly in terms of decision trees. A decision tree is a full binary tree that represents the comparisons between elements that are performed by a particular sorting algorithm operating on an input of a given size. Control, data movement, and all other aspects of the algorithm are ignored.
A lower bound for the worst case
The length of the longest simple path from the root of a decision tree to any of its reachable leaves represents the worst-case number of comparisons that the corresponding sorting algorithm performs. Consequently, the worst-case number of comparisons for a given comparison sort algorithm equals the height of its decision tree. A lower bound on the heights of all decision trees in which each permutation appears as a reachable leaf is therefore a lower bound on the running time of any comparison sort algorithm. The following theorem establishes such a lower bound.
Theorem 8.1 Any comparison sort algorithm requires $\Omega(n\lg n)$ comparisons in the worst case. Proof From the preceding discussion, it suffices to determine the height of a decision tree in which each permutation appears as a reachable leaf. Consider a decision tree of height h with l reachable leaves corresponding to a comparison sort on n elements. Because each of the $n!$ permutations of the input appears as some leaf, we have $n! \leqslant l$. Since a binary tree of height h has no more than $2^h$ leaves, we have $n! \leqslant l \leqslant 2^h$, which, by taking logarithms, implies $$ \begin{align} h & \geqslant \lg(n!) && \text{(since the lg function is monotonically increasing)} \\ & = \Omega(n\lg n) && \text{(by equation (3.19))} \end{align} $$
Corollary 8.2 Heapsort and merge sort are asymptotically optimal comparison sorts. Proof The $O(n\lg n)$ upper bounds on the running times for heapsort and merge sort match the $\Omega(n\lg n)$ worst-case lower bound from Theorem 8.1.
Exercises
8.1-1 What is the smallest possible depth of a leaf in a decision tree for a comparison sort?
Answer n-1, when the array is already sorted.
8.1-2 Obtain asymptotically tight bounds on $\lg(n!)$ without using Stirling’s approximation. Instead, evaluate the summation $\sum\limits_{k=1}^n \lg k$ using techniques from Section A.2.
Answer $\sum\limits_{k=1}^n \lg k \leqslant \sum\limits_{k=1}^n \lg n = n\lg n = O(n\lg n)$ $\sum\limits_{k=1}^n = \sum\limits_{k=2}^{\frac{n}{2}} \lg k + \sum\limits_{k=\frac{n}{2}}^n \lg k \geqslant \sum\limits_{k=1}^{\frac{n}{2}} 1 + \sum\limits_{k=\frac{n}{2}}^n\lg\frac{n}{2} = \frac{n}{2} + \frac{n}{2}(\lg n - 1) = \frac{n}{2}\lg n = O(n\lg n)$
8.1-3 Show that there is no comparison sort whose running time is linear for at least half of the $n!$ inputs of length n. What about a fraction of $\frac{1}{n}$ of the inputs of length n? What about a fraction $\frac{1}{2^n}$.
Answer
According to Theorem 8.1, we have $$ \frac{n!}{2} \leqslant n! \leqslant r \leqslant 2^h $$ Then $$ h \geqslant \lg\frac{n!}{2} = \lg(n!) - 1 = \Theta(n\lg n) - 1 = \Theta(n\lg n) $$
Simarily, for $\frac{1}{n}$ of inputs of length n $$ h \geqslant \lg\frac{n!}{n} = \lg(n!) - \lg n = \Theta(n\lg n) - \lg n = \Theta(n\lg n) $$
For $\frac{1}{2^n}$ of inputs of length n $$ h \geqslant \lg\frac{n!}{2^n} = \lg(n!) - n = \Theta(n\lg n) - n = \Theta(n\lg n) $$
8.1-4 Suppose that you are given a sequence of n elements to sort. The input sequence consists of $\frac{n}{k}$ subsequences, each containing k elements. The elements in a given subsequence are all smaller than the elements in the succeeding subsequence and larger than the elements in the preceding subsequence. Thus, all that is needed to sort the whole sequence of length n is to sort the k elements in each of the $\frac{n}{k}$ subsequences. Show an $\Omega(n\lg k)$ lower bound on the number of comparisons needed to solve this variant of the sorting problem. (Hint: It is not rigorous to simply combine the lower bounds for the individual subsequences.)
Answer $$ h \geqslant \frac{n}{k}\lg(k!) \geqslant \frac{n}{k}(\frac{k\ln k - k}{\ln 2}) = \frac{n\ln k - n}{\ln 2} = \Omega(n\lg k) $$
8.2 Counting sort
Counting sort assumes that each of the n input elements is an integer in the range 0 to k, for some integer k. When $k = O(n)$, the sort runs in $\Theta(n)$ time. Counting sort determines, for each input element x, the number of elements less than x. It uses this information to place element x directly into its position in the output array.
COUNTING-SORT(A,B,k)
let C[0...k] be a new array
for i=0 to k
C[i] = 0
for j=1 to A.length
C[A[j]] = C[A[j]] + 1
// C[i] now contains the number of elements equal to i
for i=1 to k
C[i] = C[i] + C[i-1]
// C[i] now contains the number of elements less than or equal to i
for j=A.length downto 1
B[C[A[j]]] = A[j]
C[A[j]] = C[A[j]] - 1
Each for loop takes a linear time, so the overall time of COUNTING-SORT is $\Theta(n+k)$, where n is the number of elements in the input array and k is the range of the input values.
In counting sort, no comparisons occur. It beats the lower bound of $\Omega(n\lg n)$.
An important property of counting sort is that it is stable: numbers with the same value appear in the output array in the same order as they do in the input array. That is, different satellite data with the same value of key are not shuffled.
Counting sort works efficiently for sorting integers or objects that can be mapped to integers, performs well when the range of numbers k is not significantly larger than the numebr of items n. However, it’s not suitable for sorting large ranges of numbers or floating-point numbers. And it requires additional space $O(k)$ for the count array, which can be impractical for large ranges.
Exercises
8.2-1 Using Figure 8.2 as a model, illustrate the operation of COUNTING-SORT on the array A= ⟨6,0,2,0,1,3,4,6,1,3,2⟩.
Answer After the second for loop C={2, 2, 2, 2, 1, 0, 2} After the third for loop C={2, 4, 6, 8, 9, 9, 11} After the last for loop B={0, 0, 1, 1, 2, 2, 3, 3, 4, 6, 6}
8.2-2 Prove that COUNTING-SORT is stable.
Answer In the last for loop, elements putting into output array scan sequentially and never swap any pair of element in input array. So the order of the element with the same key never changes.
8.2-3 Suppose that we were to rewrite the for loop header in line 10 of the COUNTING-SORT as for j = 1 to A.length Show that the algorithm still works properly. Is the modified algorithm stable?
Answer The algorithm still works properly because it just changes the direction of scanning. However, the stability cannot be guaranteed.
8.2-4 Describe an algorithm that, given n integers in the range 0 to k, preprocesses its input and then answers any query about how many of the n integers fall into a range [a…b] in $O(1)$ time. Your algorithm should use $\Theta(n+k)$ preprocessing time.
Answer Preprocess an array C counting number of elements less than or equal to the index, which is exactly the first 3 for loop in COUNTING-SORT, which takes $\Theta(n+k)$ time. When querying, just calculate $C[b]-C[a-1]$, which takes a constant time.
8.3 Radix sort
Radix sort is another non-comparative sorting algorithm that sorts numbers by processing individual digits.
For a d-digit number, radix sort requires a field of d places. for decimal number, it requires 10 places.
It starts from the least significant digit (LSD) to the most significant digit (MSD). This is often done using a stable sorting algorithm like counting sort or bucket sort for each digit.
For example, determine the maximum number of digit by identifying the maximum. Then sort base on the 1’s place, then 10’s place, then 100’s place, until MSD’s place is sorted.
RADIX-SORT(A,d)
for i=1 to d
use a stable sort to sort array A on digit i
Lemma 8.3 Given nd-digit numbers in which each digit can take on up to k possible values, RADIX-SORT correctly sorts these numbers in $\Theta(d(n+k))$ time if the stable sort it uses takes $\Theta(n+k)$ time. Proof The correctness of radix sort follows by induction on the column being sorted (see Exercise 8.3-3). The analysis of the running time depends on the stable sort used as the intermediate sorting algorithm. When each digit is in the range 0 to k-1 (so that it can take on k possible values), and k is not too large, counting sort is the obvious choice. Each pass over nd-digit numbers then takes time $\Theta(n+k)$. There are d passed, and so the total time for radix sort is $\Theta(d(n+k))$.
When d is constant and $k=O(n)$, we can make radix sort run in linear time. More generally, we have some flexibility in how to break each key into digits.
Lemma 8.4 Given nb-bit numbers and any positive integer $r \leqslant b$, RADIX-SORT correctly sorts these numbers in $\Theta(\frac{b}{r}(n+2^r))$ time if the stable sort it uses takes $\Theta(n+k)$ time for inputs in the range 0 to k. Proof For a value $r \leqslant b$, we view each key as having $d = \lceil \frac{b}{r} \rceil$ digits of r bits each. Each digit is an integer in the range 0 to $2^r-1$, so that we can use counting sort with $k=2^r-1$. (For example, we can view a 32-bit word as having four 8-bit digits, so that $b=32,r=8,k=2^r-1=255$, and $d=\frac{b}{r}=4$.) Each pass of counting sort takes time $\Theta(n+k) = \Theta(n+2^r)$ and there are d passes, for a total running time of $\Theta(d(n+2^r)) = \Theta(\frac{b}{r}(n+2^r))$.
For given values of n and b, we wish to choose the value of r, with $r \leqslant b$, that minimizes the expression $\frac{b}{r}(n+2^r)$.
If $b < \lfloor \lg n \rfloor$, then for any value of $r \leqslant b$, we have that $(n+2^r)=\Theta(n)$. Thus, choosing $r=b$ yields a running time of $\frac{b}{b}(n+2^b)=\Theta(n)$, which is asymptotically optimal.
If $b \geqslant \lfloor \lg n \rfloor$, then choosing $r = \lfloor \lg n \rfloor$ gives the best time to within a constant factor, which we can see follows. Choosing $r = \lfloor \lg n \rfloor$ yields a running time of $\Theta(\frac{bn}{\lg n})$. As we increase r above $\lfloor \lg n \rfloor$, the $2^r$ term in the numerator increases faster than the r term in the denominator, and so increasing r above $\lfloor \lg n \rfloor$ yields a running time of $\Omega(\frac{bn}{\lg n})$. If instead we were to decrease r below $\lfloor \lg n \rfloor$, then the $\frac{b}{r}$ term increases and the $n+2^r$ term remains at $\Theta(n)$.
If $b=O(\lg n)$, as is often the case, and we choose $r \approx \lg n$, then radix sort’s running time is $\Theta(n)$, which appears to be better than quicksort’s expected running time of $\Theta(n\lg n)$. However, although radix sort may make fewer passes than quicksort over the n keys, each pass of radix sort may take significantly longer. And quicksort often uses hardware caches more effectively than radix sort. Moreover, the version of radix sort that uses counting sort as the intermediate stable sort does not sort in place, which many of the $\Theta(n\lg n)$-time comparison sorts do. Thus, when primary memory storage is at a premium, we might prefer an in-place algorithm such as quicksort.
Exercises
8.3-1 Using Figure 8.3 as a model, illustrate the operation of RADIX-SORT on the following list of English words: COW, DOG, SEA, RUG, ROW, MOB, BOX, TAB, BAR, EAR, TAR, DIG, BIG, TEA, NOW, FOX.
Answer
1
2
3
4
COW
SEA
TAB
BAR
DOG
TEA
BAR
BIG
SEA
MOB
EAR
BOX
RUG
TAB
TAR
COW
ROW
DOG
SEA
DIG
MOB
RUG
TEA
DOG
BOX
DIG
DIG
EAR
TAB
BIG
BIG
FOX
BAR
BAR
MOB
MOB
EAR
EAR
DOG
NOW
TAR
TAR
COW
ROW
DIG
COW
ROW
ROG
BIG
ROW
NOW
SEA
TEA
NOW
BOX
TAB
NOW
BOX
FOX
TAR
FOX
FOX
ROG
TEA
8.3-2 Which of the following sorting algorithms are stable: insertion sort, merge sort, heapsort, and quicksort? Give a simple scheme that makes any sorting algorithm stable. How much additional time and space does your scheme entail?
Answer Insertion sort and merge sort are stable, while heapsort and quicksort are not. Assign an extra number of original index to every element. After sorting, sort those elements with the same key by the extra number. It requires double space. However, the running time is not asymptotically changed.
8.3-3 Use induction to prove that radix sort works. Where does your proof need the assumption that the intermediate sort is stable?
Answer We know if a sequence of numbers are sorted, the numbers of every place digit are sorted, and vice versa. Loop invariant: At the beginning of each iteration, the last i-1 digits are sorted. Initialization: At the beginning of the loop, it’s trivial that array of the last 0 digits are sorted. Maintenance: Since radix sort is stable, after the array of i-th digits are sorted, the array of (i-1)-th digits are still sorted. Termination: The loop terminates when $i=d+1$. And the numbers of every place digit are sorted. Since the loop invariant holds, the array is sorted.
8.3-4 Show how to sort n integers in the range 0 to $n^3-1$ in $O(n)$ time.
Answer Apply radix sort. Consider those integers as n-digit integers. Since those integers are in the range 0 to $n^3-1$, the maximum number of digits is $\log_n n^3 = 3$. Then the running time is $O(d(n+k)) = O(3(n+n)) = O(6n) = O(n)$.
8.3-5 In the first card-sorting algorithm in this section, exactly how many sorting passes are needed to sort d-digit decimal numbers in the worst case? How many piles of cards would an operator need to keep track of in the worst case?
Answer Given nd-digit numbers in which each digit can take on up to k possible values, then there are $\Theta(k^d)$ passes and $\Theta(nk)$ piles in the worst case.
8.4 Bucket sort
Bucket sort divides the interval [0,1) into n equal-sized subintervals, or buckets, and then distributes the n input numbers into the buckets. Out code for bucket sort assumes that the input is an n-element array A and that each element A[i] in the array satisfies $0 \leqslant A[i] < 1$.
BUCKET-SORT(A)
n = A.length
let B[0...n-1] be a new array
for i=0 to n-1
make B[i] an empty list
for i=i to n
insert A[i] into list B[⌊nA[i]⌋]
for i=0 to n-1
sort list B[i] with insertion sort
concatenate the lists B[0],B[1],...,B[n-1] together in order
Correctness proof
Consider two elements A[i] and A[j]. Assume without loss of generality that $A[i] \leqslant A[j]$. Since $\lfloor n A[i] \rfloor \leqslant \lfloor n A[j] \rfloor$, either element A[i] goes into the same bucket as A[j] or it goes into a bucket with a lower index. If A[i] and A[j] go into the same bucket, then the for loop of lines 8-9 puts them into the proper order. If A[i] and A[j] go into different buckets, then line 10 puts them into the proper order. Therefore, bucket sort works correctly
Running time analysis
Let $n_i$ be the random variable denoting the number of elements placed in bucket B[i]. Since insertion sort runs in quadratic time, the running time of bucket sort is $$ T(n) = \Theta(n) + \sum_{i=0}^{n-1} O(n_i^2) $$ Taking expectations of both sides and using linearity of expectation, we have $$ \begin{align} \mathrm{E}[T(n)] &= \mathrm{E}\left[ \Theta(n) + \sum_{i=0}^{n-1} O(n_i^2) \right] \\ &= \Theta(n) + \sum_{i=0}^{n-1} \mathrm{E}[O(n_i^2)] && \text{(by linearity of expectation)} \\ &= \Theta(n) + \sum_{i=0}^{n-1} \mathrm{E}[O(n_i^2)] && \text{(by equation (C.22))} \tag{8.1} \end{align} $$ We claim that $$ \mathrm{E}[n_i^n] = 2 - \frac{1}{n} \tag{8.2} $$ for $i=0,1,…,n-1$.
To prove equation (8.2), we define indicator random variables $X_{ij} = I \lbrace A[j] \text{falls in bucket i} \rbrace$ for $i=0,1,…,n-1$ and $j=1,2,…,n$. Thus, $n_i = \sum\limits_{j=1}^n X_{ij}$. To compute $\mathrm{E}[n_i^2]$, we expand the square and regroup terms: $$ \begin{align} \mathrm{E}[T(n)] &= \mathrm{E} \left[ \left( \sum_{j=1}^n X_{ij} \right)^2 \right] \\ &= \mathrm{E} \left[ \sum_{j=1}^n \sum_{k=1}^n X_{ij}X_{ik} \right] \\ &= \mathrm{E} \left[ \sum_{j=1}^n X_{ij}^2 + \sum_{1 \leqslant j \leqslant n}\, \sum_{\substack{1 \leqslant k \leqslant n \\ k \ne j}} X_{ij}X_{ik} \right] \\ &= \sum_{j=1}^n \mathrm{E}[X_{ij}^2] + \sum_{1 \leqslant j \leqslant n}\, \sum_{\substack{1 \leqslant k \leqslant n \\ k \ne j}} \mathrm{E}[X_{ij}X_{ik}] \tag{8.3} \end{align} $$ where the last line follows by linearity of expectation.
We evaluate the two summations separately. Indicator random variable $X_{ij}$ is 1 with probability $\frac{1}{n}$ and 0 otherwise, and therefore $$ \begin{align} \mathrm{E}[X_{ij}^2] &= 1^2 \cdot \frac{1}{n} + 0^2 \cdot \left( 1 - \frac{1}{n} \right) \\ &= \frac{1}{n} \end{align} $$
When $k \ne j$, the variables $X_{ij}$ and $X_{ik}$ are independent, and hence $$ \begin{align} \mathrm{E}[X_{ij}X_{ik}] &= \mathrm{E}[X_{ij}]\mathrm{E}[X_{ik}] \\ &= \frac{1}{n} \cdot \frac{1}{n} \\ &= \frac{1}{n^2} \end{align} $$
Substituting these two expected values in equation (8.3), we obtain $$ \begin{align} \mathrm{E}[n_i^2] &= \sum_{j=1}^n \frac{1}{n} + \sum_{1 \leqslant j \leqslant n}\, \sum_{\substack{1 \leqslant k \leqslant n \\ k \ne j}} \frac{1}{n^2} \\ &= n \cdot \frac{1}{n} + n(n-1) \cdot \frac{1}{n^2} \\ &= 1 + \frac{n-1}{n} \\ &= 2 - \frac{1}{n} \end{align} $$ which proves equation (8.2).
Using this expected value in equation (8.1), we conclude that the average-case running time for bucket sort is $\Theta(n) + n \cdot O(2 - \frac{1}{n}) = \Theta(n)$.
Exercises
**8.4-1 Using Figure 8.4 as a model, illustrate the operation of BUCKET-SORT on the array A=⟨.79,.13,.16,.64,.39,.20,.89,.53,.71,.42⟩.
8.4-2 Explain why the worst-case running time for bucket sort is $\Theta(n^2)$. What simple change to the algorithm preserves its linear average-case running time and makes its worst-case running time $O(n\lg n)$?
Answer If all the keys fall in the same bucket, and they happen to be in reverse sorted order, the worst case occurs. In this case, it takes $\Theta(n^2)$ time to sort a single bucket filled with n reverse sorted elements by insertion sort. In order to make the worst-case running time $O(n\lg n)$, we can replace insertion sort with merge sort or heap sort.
8.4-3 Let X be a random variable that is equal to the number of heads in two flips of a fair coin. What is $\mathrm{E}[X^2]$? What is $\mathrm{E}^2[X]$?
Answer When flipping a fair coin twice, the possible outcomes are:
8.4-4 * We are given n points in the unit circle, $p_i = (x_i, y_i)$, such that $0 < x_i^2 + y_i^2 \leqslant 1$ for $i=1.2….,n$. Suppose that the points are uniformly distributed; that is, the probability of finding a point in any region of the circle is proportional to the area of that region. Design an algorithm with an average-case running time of $\Theta(n)$ to sort the n points by their distances $d_i = \sqrt{x_i^2 + y_i^2}$ from the origin. (Hint: Design the bucket sizes in BUCKET-SORT to reflect the uniform distribution of the points in the unit circle.)
Answer Divide n rings with the same area (the innermost one is a circle). Then sort the distances by bucket sort. Let r be the difference of radii between two closest ring circle. $$ \begin{align} \pi r_i^2 &= \frac{i}{n} \cdot \pi \cdot 1^2 \\ r &= \sqrt{\frac{i}{n}} \end{align} $$
8.4-5 * A probability distribution function $P(x)$ for a random variable X is defined by $P(x) = \mathrm{Pr}\lbrace X \leqslant x \rbrace$. Suppose that we draw a list of n random variables $X_1,X_2,…,X_n$ from a continuous probability distribution function P that is computable in $O(1)$ time. Give an algorithm that sorts these numbers in linear average-case time.
Answer Bucket sort by $p_i$. Divide n buckets: $[p_0,p_1),[p_1,p_2),…,[p_{n-1},p_n)$.
Problems
TODO
9. Medians and Order Statistics
9.1 Minimum and maximum
MINIMUM(A)
min = A[1]
for i=2 to A.length
if min > A[i]
min = A[i]
return min
Observing that every element except the winner must lose at least one match, we conclude that n-1 comparisons are necessary to determine the minimum. Hence, the algorithm MINIMUM is optimal with respect to the number of comparisons performed.
Simultaneous minimum and maximum
We can find both the minimum and maximum using at most $3\lfloor\frac{n}{2}\rfloor$ comparisons. We do so by maintaining both the minimum and maximum elements seen thus far.
Instead of comparing the elements against the current minimum and maximum, at a cost of 2 comparisons per element, we process elements in pairs. We do comparison for 2 elements, then compare the smaller with the current minimum and the larger to the current maximum, at a cost of 3 comparisons for every 2 elements.
If n is odd, we set both the minimum and maximum to the value of the first element. In this case, we perform $3\lfloor\frac{n}{2}\rfloor$ comparisons.
If n is even, we perform 1 comparison on the first 2 elements to determine the initial values of minimum and maximum. In this case, we perform 1 initial comparison followed by $\frac{3(n-2)}{2}$ comparisons, for a total of $\frac{3n}{2} - 2$
In either case, the total number of comparisons is at most $3\lfloor\frac{n}{2}\rfloor$.
Exercises
9.1-1 Show that the second smallest of n elements can be found with $n + \lceil \lg n \rceil - 2$ comparisons in the worst case. (Hint: Also find the smallest element.)
Answer When we find the smallest element, we can maintain a list of elements that lost in the comparisons to this smallest element. To find the smallest element, we should do n-1 comparisons. In the worst case, the smallest element is compared to $\lceil \log_2 n \rceil$ elements (the height of the comparison tree), which requires $\lceil \log_2 n \rceil - 1$ comparisons. So the total comparisons are $n + $\lceil \log_2 n \rceil$ - 2$.
By the way, in brute-force algorithm, if the current smallest element loses the comparison, we can assign it to a variable. If the current smallest element wins, we compare the candidate with this variable. In this algorithm, the best case requires n-1 comparisons, however the worst case requires 2n-2 comparisons.
9.1-2 * Prove the lower bound of $\lceil \frac{3n}{2} \rceil - 2$ comparisons in the worst case to find both the maximum and minimum of n numbers. (Hint: Consider how many numbers are potentially either the maximum or minimum, and investigate how a comparison affects these counts.)
Answer If n is odd, we need $3\lfloor\frac{n}{2}\rfloor = \lfloor\frac{3n}{2}\rfloor = \lceil \frac{3n}{2} \rceil - 2$ comparisons. If n is even, we need $\frac{3n}{2} - 2 = \lceil \frac{3n}{2} \rceil - 2$ comparisons. In either case, the total number of comparisons is $\lceil \frac{3n}{2} \rceil - 2$.
9.2 Selection in expected linear time
The following code for RANDOMIZED-SELECT returns the i-th smallest element of the array A[p…r]
RANDOMIZED-SELECT(A,p,r,i)
if p == r
return A[p]
q = RANDOMIZED-PARTITION(A,p,r)
k = q - p + 1
if i == k // the pivot value is the answer
return A[q]
else if i < k
return RANDOMIZED-SELECT(A,p,q-1,i)
else
return RANDOMIZED-SELECT(A,q+1,r,i-k)
The worst-case running time for RANDOMIZED-SELECT is $\Theta(n^2)$, even to find the minimum, and partitioning takes $\Theta(n)$ time. However, this algorithm has a linear expected running time. And because it is randomized, no particular input elicits the worst-case behavior.
Analysis of running time: TODO
Exercises
9.2-1 Show that RANDOMIZED-SELECT never makes a recursive call to a 0-length array
Answer If the length of the array is 0, then $p=r$, which makes RANDOMIZED-SELECT return a value instead of recursive call.
9.2-2 Argue that the indicator random variable $X_k$ and the value $T(\max(k-1,n-k))$ are independent.
Answer Whatever $X_k$ is, $T(\max(k-1,n-k))$ won’t be changed. So they are independent.
9.2-3 Write an iterative version of RANDOMIZED-SELECT.
Answer
RANDOMIZED-SELECT(A,p,r,i)
while true
if p == r
return A[p]
q = RANDOMIZED-PARTITION(A, p, r)
k = q - p + 1
if i == k
return A[q]
if i < k
r = q - 1
else
p = q + 1
i = i - k
9.2-4 Suppose we use RANDOMIZED-SELECT to select the minimum element of the array A=⟨3,2,9,0,7,5,4,8,6,1⟩. Describe a sequence of partitions that results in a worst-case performance of RANDOMIZED-SELECT.
Answer ⟨9,8,7,6,5,4,3,2,1,0⟩
9.3 Selection in worst-case linear time
The SELECT algorithm determines the ith smallest of an input array of $n>1$ distinct elements by executing the following steps. (If $n=1$, then SELECT merely returns its only input value as the ith smallest.)
Divide the n elements of the input array into $\lfloor\frac{n}{5}\rfloor$ groups of 5 elements each and at most one group made up of the remaining n mod 5 elements.
Find the median of each of the $\lfloor\frac{n}{5}\rfloor$ groups by first insertion-sorting the elements of each group (of which there are at most 5) and then picking the median from the sorted list of group elements.
Use SELECT recursively to find the median x of the $\lfloor\frac{n}{5}\rfloor$ medians found in step 2. (If there are an even number of medians, then by our convention, x is the lower median.)
Partition the input array around the median-of-medians x using the modified version of PARTITION. Let k be one more than the number of elements on the low side of the partition, so that x is the kth smallest element and there are $n-k$ elements on the high side of the partition.
If $i=k$, then return x. Otherwise, use SELECT recursively to find the ith smallest element on the low side if $i<k$ or the $i-k$th smallest element on the high side if $i>k$.
Analysis of running time
The number of elements greater than x is at least $$ 3\left( \left\lceil \frac{1}{2} \left\lceil \frac{n}{5} \right\rceil \right\rceil - 2 \right) \geqslant \frac{3n}{10} - 6 $$ Similarly, at least $\frac{3n}{10}-6$ elements are less than x. Thus, in the worst case, step 5 calls SELECT recursively on at most $\frac{7n}{10} + $ elements.
Step 1,2, and 4 take $O(n)$ time. Step 3 takes time $T(\lceil\frac{n}{5}\rceil)$, and step 5 takes time at most $T(\frac{7n}{10} + 6)$, assuming that T is monotonically increasing. We make the assumption, which seems unmotivated at first, that any input of fewer than 140 elements requires $O(1)$ time; the origin of the magic constant 140 will be clear shortly. We can therefore obtain the recurrence $$ T(n) \leqslant \begin{align} \begin{cases} O(1) & \quad\text{if } n < 140 \\ T(\lceil\cfrac{n}{5}\rceil) + T(\cfrac{7n}{10}+6) + O(n) & \quad\text{if } n \geqslant 140 \end{cases} \end{align} $$
Assume that $T(n) \leqslant cn$ for some suitably large constant c and all $n<140$, substituting into the recurrence yields
$$ \begin{align} T(n) & \leqslant c\lfloor\frac{n}{5}\rfloor + c(\frac{7n}{10} + 6) + an \\ & \leqslant \frac{cn}{5} + c + \frac{7n}{10} + 6c + an \\ & = \frac{9cn}{10} + 7c + an \\ & = cn + (-\frac{cn}{10} + 7c + an) \end{align} $$ which is at most $cn$ if $$ -\frac{cn}{10} + 7c + an \leqslant 0 \tag{9.2} $$ Inequality (9.2) is equivalent to the inequality $c \geqslant 10a(\frac{n}{n-70})$ when $n > 70$. Because we assume that $n \geqslant 140$, we have $\frac{n}{n-70} \leqslant 2$, and so choosing $c \geqslant 20a$ will satisfy inequality (9.2). (Note that there is nothing special about the constant 140; we could replace it by any integer strictly greater than 70 and then choose c accordingly.) The worst-case running time of SELECT is therefore linear.
Exercises
TODO
Problem
TODO
PART III: DATA STRUCTURES
Whereas mathematical sets are unchanging, the sets manipulated by algorithms can grow, shrink, or otherwise change over time. We call such sets dynamic. Algorithms may require several different types of operations to be performed on sets. For example, many algorithms need only the ability to insert elements into, delete elements from, and test membership in a set. We call a dynamic set that supports these operations a dictionary.
10. Elementary Data Structures
10.1 Stacks and queues
In a stack, the element deleted from the set is the one most recently inserted: the stack implements a last-in, first-out, or LIFO, policy. In a queue, the element deleted is always the one that has been in the set for the longest time: the queue implements a fisrt-in, first-out, or FIFO, policy.
Stacks
The INSERT operation on a stack is often called PUSH, and the DELETE operation is often called POP.
We can implement a stack of at most n elements with an arrayS[1…n]. The array has an attribute S.top that indexes the most recently inserted element. The stack consists of elements S[1…S.top], where S[1] is the element at the bottom of the stack and S[S.top] is the element at the top.
When S.top=0, the stack contains no elements and is empty. We can test to see whether the stack is empty by query operation STACK-EMPTY. If we attempt to pop an empty stack, we say the stack underflows, which is normally an error. If S.top exceeds n, the stack overflows.
In our pseudocode implementation, we don’t worry about stack overflow.
Queues
We call the INSERT operation on a queue ENQUEUE, and we call the DELETE operation DEQUEUE.
The queue has a head and a tail. When an element is enqueued, it takes its place at the tail of the queue. The element dequeued is always the one at the head of the queue.
The attribute Q.tail indexes the next location at which a newly arriving element will be inserted into the queue.
As the figure shown below, the elements in the queue reside in locations Q.head, Q.head+1, …, Q.tail - 1, where we “wrap around” in the sense that location 1 immediately follows location n in a circular order.
When Q.head=Q.tail, the queue is empty. Initially, we have Q.head=Q.tail=1. If we attempt to dequeue an element from an empty queue, the queue underflows. When Q.head=Q.tail+1 or both Q.head=1 and Q.tail=Q.length, the queue is full, and if we attempt to enqueue an element, then the queue overflows.
ENQUEUE(Q,x)
Q[Q.tail] = x
if Q.tail == Q.length
Q.tail = 1
else
Q.tail = Q.tail + 1
DEQUEUE(Q)
x = Q[Q.head]
if Q.head == Q.length
Q.head = 1
else
Q.head = Q.head + 1
return x
The pseudocode omits the error checking for underflow and overflow. You can check the error-detecting version in exercise 10.1-4.
Exercises
10.1 Using Figure 10.1 as a model, illustrate the result of each operation in the sequence PUSH(S,4), PUSH(S,1), PUSH(S, 3), POP(S), PUSH(S, 8), and POP(S) on an initially empty stack S stored in array S[1…6].
Answer
1
2
3
4
5
6
4
1
2
3
4
5
6
4
1
1
2
3
4
5
6
4
1
3
1
2
3
4
5
6
4
1
1
2
3
4
5
6
4
1
8
1
2
3
4
5
6
4
1
10.1-2 Explain how to implement two stacks in one array A[1…n] in such a way that neither stack overflows unless the total number of elements in both stacks together is n. The PUSH and POP operations should run in $O(1)$ time.
Answer One stack starts from index 1 and grows increasingly, while another stack starts from index n and grows decreasingly. When two tops of stacks point to the same index, the insertion causes the overflow error.
10.1-3 Using Figure 10.2 as a model, illustrate the result of each operation in the sequence ENQUEUE(Q, 4), ENQUEUE(Q, 1), ENQUEUE(Q, 3), DEQUEUE(Q), ENQUEUE(Q, 8), and DEQUEUE(Q) on an initially empty queue Q stored in array Q[1…6].
Answer
1
2
3
4
5
6
4
1
2
3
4
5
6
4
1
1
2
3
4
5
6
4
1
3
1
2
3
4
5
6
1
3
1
2
3
4
5
6
1
3
8
1
2
3
4
5
6
3
8
10.1-4 Rewrite ENQUEUE and DEQUEUE to detect underflow and overflow of a queue.
Answer
ENQUEUE(Q,x)
if Q.head == Q.tail+1 or (Q.head == 1 and Q.tail == Q.length)
error "overflow"
Q[Q.tail] = x
if Q.tail == Q.length
Q.tail = 1
else
Q.tail = Q.tail + 1
DEQUEUE(Q)
if Q.head == Q.tail
error "underflow"
x = Q[Q.head]
if Q.head == Q.length
Q.head = 1
else
Q.head = Q.head + 1
return x
10.1-5 Whereas a stack allows insertion and deletion of elements at only one end, and a queue allows insertion at one end and deletion at the other end, a deque (double-ended queue) allows insertion and deletion at both ends. Write four $O(1)$-time procedures to insert elements into and delete elements from both ends of a deque implemented by an array.
The procedure TAIL-ENQUEUE and HEAD-DEQUEUE is the same in queue. Answer
QUEUE-FULL(A)
return Q.head == Q.tail+1 or (Q.head == 1 and Q.tail == Q.length)
QUEUE-EMPTY(A)
return Q.head == Q.tail
HEAD-ENQUEUE(A,x)
if QUEUE-FULL(A)
error "overflow"
if Q.head == 1
Q.head = Q.length
else
Q.head = Q.head - 1
Q[Q.head] = x
TAIL-ENQUEUE(A,x)
if QUEUE-FULL(A)
error "overflow"
Q[Q.tail] = x
if Q.tail == Q.length
Q.tail = 1
else
Q.tail = Q.tail + 1
HEAD-DEQUEUE(A)
if QUEUE-EMPTY(A)
error "underflow"
x = Q[Q.head]
if Q.head == Q.length
Q.head = 1
else
Q.head = Q.head + 1
return x
TAIL-DEQUEUE(A)
if QUEUE-EMPTY(A)
error "underflow"
if Q.tail == 1
Q.tail = Q.length
else
Q.tail = Q.tail - 1
return A[Q.tail]
10.1-6 Show how to implement a queue using two stacks. Analyze the running time of the queue operations.
Answer Let two stacks be A and B. When pushing a new element, push it into A. When popping an element, pop all elements from A and push them to B, then pop an element from B. Running time of push: $O(1)$. Running time of pop: In worst-case it is $O(n)$, where n is the number of elements of A.
10.1-7 Show how to implement a stack using two queues. Analyze the running time of the stack operations.
Answer Let two queues be A and B. When enqueueing a new element, enqueue it into A. When dequeueing an element, dequeue all elements from A and enqueue them to B, then dequeue an element from B. Running time of enqueue: $O(1)$. Running time of dequeue: In worst-case it is $O(n)$, where n is the number of elements of A.
10.2 Linked lists
A linked list is a data structure in which the objects are arranged in a linear order. The order in a linked list is determined by a pointer in each object.
Each element of a doubly linked listL is an object with an attribute key and two other pointer attributes: next and prev. The object may also contain other satellite data.
If x.prev = NIL, the element x has no predecessor and is therefore the first element, or head, of the list.
If x.next = NIL, the element x has no successor and is therefore the last element, or tail, of the list.
If L.head = NIL, the list is empty.
If a list is singly linked, we omit the prev pointer in each element. If a list is sorted, the linear order of the list corresponds to the linear order of keys stored in elements of the list; the minimum element is then the head of the list, and the maximum element is the tail. If the list is unsorted, the elements can appear in any order.
In a circular list, the prev pointer of the head of the list points to the tail, and the next pointer of the tail of the list points to the head.
Searching a linked list
LIST-SEARCH(L,k)
x = L.head
while x != NIL and x.key != k
x = x.next
return x
To search a list of n object, the LIST-SEARCH procedure takes $\Theta(n)$ time in the worst case, since it may have to search the entire list.
Inserting into a linked list
The LIST-INSERT procedure “splices” x onto the front of the linked list
LIST-INSERT(L,x)
x.next = L.head
if L.head != NIL
L.head.prev = x
L.head = x
x.prev = NIL
The running time for LIST-INSERT on a list of n elements is $O(1)$.
Deleting from a linked list
The procedure LIST-DELETE removes an element x from a linked list L. It must be given a pointer to x. If we wish to delete an element with a given key, we must first call LIST-SEARCH to retrieve a pointer to the element.
LIST-DELETE(L,x)
if x.prev != NIL
x.prev.next = x.next
else
L.head = x.next
if x.next != NIL
x.next.prev = x.prev
LIST-DELETE runs in $O(1)$ time.
Sentinels
The code for LIST-DELETE would be simpler if we could ignore the boundary conditions at the head and tail of the list:
A sentinel is a dummy object that allows us to simplify boundary conditions. For example, we can put an element L.nil between head and tail, then it turns a regular doubly linked list into a circular, doubly linked list with a sentinel. The attribute L.nil.next points to the head of the list, and L.nil.prev points to the tail.
Then
LIST-SEARCH'(L,k)
x = L.nil.next
while x != L.nil and x.key != k
x = x.next
return x
LIST-INSERT'(L,x)
x.next = L.nil.next
L.nil.next.prev = x
L.nil.next = x
Exercises
10.2-1 Can you implement the dynamic-set operation INSERT on a singly linked list in $O(1)$ time? How about DELETE?
Answer
SINGLY-LIST-INSERT(L,x)
x.next = L.head
L.head = x
L.nil.next = x // if using sentinel
For DELETE, we need to find the previous element of x, which takes $O(n)$ time in the worst case.
10.2-2 Implement a stack using a singly linked list L. The operations PUSH and POP should still take $O(1)$ time.
Answer
PUSH(L,x)
x.next = L.head
L.head = x
POP(L)
if L.head == NIL // list is empty
error "underflow"
else
x = L.head
L.head = L.head.next
return x
10.2-3 Implement a queue by a singly linked list L. The operations ENQUEUE and DEQUEUE should still take $O(1)$ time.
Answer
QUEUE-EMPTY(L)
return L.head == NIL
ENQUEUE(L,x)
if QUEUE-EMPTY(L)
L.head = x
else
L.tail.next = x
L.tail = x
DEQUEUE(L)
if QUEUE-EMPTY(L)
error "underflow"
x = L.head
if x.next == NIL
L.head = NIL
else
L.head = x.next
return x
10.2-4 As written, each loop iteration in the LIST-SEARCH’ procedure requires two tests: one for $x \ne L.nil$ and one for $x.key \ne k$. Show how to eliminate the test for $x \ne L.nil$ in each iteration.
Answer The test $x \ne L.nil$ is to prevent endless loop, since the list is circular. In order to eliminate this check, we should make the loop terminate when checking x.nil. So we can assign k to the key of x.nil, then if there is no key equal to k except x.nil, the element x.nil will be returned.
LIST-SEARCH'(L,k)
x = L.nil.next
L.nil.key = k
while x.key != k
x = x.next
return x
10.2-5 Implement the dictionary operations INSERT, DELETE, and SEARCH using singly linked, circular lists. What are the running times of your procedures?
Answer
INSERT(L,x)
x.next = L.nil.next
L.nil.next = x
DELETE(L,x)
prev = L.nil
while prev.next != x
if prev.next == L.nil
error "element x does not exist"
prev = prev.next
prev.next = x.next
SEARCH(L,k)
x = L.nil.next
while x != L.nil and x.key != k
x = x.next
return x
10.2-6 The dynamic-set operation UNION takes two disjoint sets $S_1$ and $S_2$ as input, and it returns a set $S=S_1 \cup S_2$ consisting of all the elements of $S_1$ and $S_2$. The sets $S_1$ and $S_2$ are usually destroyed by the operation. Show how to support UNION in $O(1)$ time using a suitable list data structure.
Answer If $S_1$ and $S_2$ are simply linked lists:
UNION(S1,S2)
if S1.tail != NIL
S1.tail.next = S2.head
S1.tail = S2.tail
if S1.head == NIL
S1.head = S2.head
return S1
10.2-7 Give a $\Theta(n)$-time nonrecursive procedure that reverses a singly linked list of n elements. The procedure should use no more than constant storage beyond that needed for the list itself.
Answer
REVERSE(L)
x = L.head
y = x.next
x.next = NIL
while y != NIL
z = y.next
y.next = x
x = y
y = z
L.head = x
10.2-8 Explain how to implement doubly linked lists using only one pointer value x.np per item instead of the usual two (next and prev). Assume that all pointer values can be interpreted as k-bit integers, and define x.np to be x.np = x.next XOR x.prev, the k-bit “exclusive-or” of x.next and x.prev. (The value NIL is represented by 0.) Be sure to describe what information you need to access the head of the list. Show how to implement the SEARCH, INSERT, and DELETE operations on such a list. Also show how to reverse such a list in $O(1)$ time.
Answer We know if x XOR y = z, we can get x or y by y = z XOR x, x = z XOR y.
LIST-SEARCH(L,k)
prev = NIL
x = L.head
while x != NIL and x.key != k
next = prev XOR x.np
prev = x
x = next
return x
LIST-INSERT(L, x)
x.np = NIL XOR L.tail
if L.tail != NIL
L.tail.np = (L.tail.np XOR NIL) XOR x
if L.head == NIL
L.head = x
L.tail = x
LIST-DELETE(L, x)
y = L.head
prev = NIL
while y != NIL
next = prev XOR y.np
if y != x
prev = y
y = next
else
if prev != NIL
prev.np = (prev.np XOR y) XOR next
else L.head = next
if next != NIL
next.np = prev XOR (y XOR next.np)
else L.tail = prev
LIST-REVERSE(L)
tmp = L.head
L.head = L.tail
L.tail = tmp
10.3 Implementing pointers and objects
A multiple-array representation of objects
We can represent a collection of objects that have the same attributes by using an array for each attribute. For example, for a given array index x, the array entries key[x], next[x], prev[x] represent an object in the linked list. Under this interpretation, a pointer x is simply a common index into the key, next, and prev arrays. For NIL, we usually use an integer (such as 0 or -1) that cannot possibly represent an actual index into the arrays.
A single-array representation of objects
An object occupies a contiguous subarray A[j…k]. Each attribute of the object corresponds to an offset in the range from 0 to $k-j$, and a pointer to the object is the index j. For example, an element consists of three integers: key, next, and prev, and the offsets corresponding to them are 0, 1, and 2. To read the value of i.prev, given a pointer i, we add the value i of the pointer to the offset 2, thus reading A[i+2]. The single-array representation is flexible in that it permits objects of different lengths to be stored in the same array.
Allocating and freeing objects
To insert a key into a dynamic set represented by a doubly linked list, we must allocate a pointer to a currently unused object in the linked-list representation. In some systems, a garbage collector is responsible for determining which objects are unused.
Suppose that the arrays in the multiple-array representation have length m and that at some moment the dynamic set contains $n \leqslant m$ elements. Then n objects represent elements currently in the dynamic set, and the remaining $m-n$ objects are free; the free objects are available to represent elements inserted into the dynamic set in the future.
We keep the free objects in a singly linked list, which we call the free list. The free list uses only the next array, which stores the next pointers within the list. The head of the free list is held in the global variable free. When the dynamic set represented by linked list L is nonempty, the free list may be intertwined with list L. Note that each object in the representation is either in list L or in the free list, but not in both.
The free list acts like a stack: the next object allocated is the last one freed. We can use a list implementation of the stack operations PUSH and POP to implement the procedures for allocating and freeing objects, respectively. We assume that the global variable free used in the following procedures points to the first element of the free list.
ALLOCATE-OBJECT()
if free == NIL
error "out of space"
else
x = free
free = x.next
return x
FREE-OBJECT(x)
x.next = free
free = x
The free list initially contains all n unallocated objects. Once the free list has been exhausted, running the ALLOCATE-OBJECT procedure signals an error. We can even service several linked lists with just a single free list.
Exercises
10.3-1 Draw a picture of the sequence ⟨13, 4, 8, 19, 5, 11⟩ stored as a doubly linked list using the multiple-array representation. Do the same for the single-array representation.
Answer The multiple-array representation:
index
1
2
3
4
5
6
7
key
13
4
8
19
5
11
next
3
4
5
6
7
/
prev
/
2
3
4
5
6
The single-array representation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
13
3
/
4
7
1
8
10
4
19
13
7
5
16
10
11
/
13
10.3-2 Write the procedures ALLOCATE-OBJECT and FREE-OBJECT for a homogeneous collection of objects implemented by the single-array representation.
Answer
ALLOCATE-OBJECT()
if free == NIL
error "out of space"
else x = free
free = A[x + 1]
return x
FREE-OBJECT(x)
A[x + 1] = free
free = x
10.3-3 Why don’t we need to set or reset the prev attributes of objects in the implementation of the ALLOCATE-OBJECT and FREE-OBJECT procedures?
Answer Because the free list is like a stack, prev is not needed.
10.3-4 It is often desirable to keep all elements of a doubly linked list compact in storage, using, for example, the first m index locations in the multiple-array representation.(This is the case in a paged, virtual-memory computing environment.) Explain how to implement the procedures ALLOCATE-OBJECT and FREE-OBJECT so that the representation is compact. Assume that there are no pointers to elements of the linked list outside the list itself. (Hint: Use the array implementation of a stack.)
Answer TODO
10.3-5
TODO
10.4 Representing rooted trees
We represent each node of a tree by an object. As with linked lists, we assume that each node contains a key attribute. The remaining attributes of interest are pointers to other nodes, and they vary according to the type of tree.
Binary trees
We can use the attributes p, left, and right to store pointers to the parent, left child, and right child of each node in a binary tree T. If x.p = NIL, then x is the root. If node x has no left child, then x.left = NIL, and similarly for the right child. The root of the entire tree T is pointed to by the attribute T.root. If T.root = NIL. then the tree is empty.
Rooted trees with unbounded branching
The left-child, right-sibling representation Except the parent pointer $x.p$, each node x has only two pointers:
x.left-child points to the leftmost child of node x
x.right-sibling points to the sibling of x immediately to its right.
If node x has no children, then x.left-child = NIL. If node x is the right most child of its parent, then x.right-sibling = NIL.
Other tree representations
For example, the heap represented in chapter 6, which is based on a complete binary tree, by a single array plus the index of the last node in the heap.
Except that, many other schemes are possible. Which scheme is best depends on the application.
Exercises
10.4-1 Draw the binary tree rooted at index 6 that is represented by the following attributes: | index | key | left | right | |:—–:|:—:|:—-:|:—–:| | 1 | 12 | 7 | 3 | | 2 | 15 | 8 | NIL | | 3 | 4 | 10 | NIL | | 4 | 10 | 5 | 9 | | 5 | 2 | NIL | NIL | | 6 | 18 | 1 | 4 | | 7 | 7 | NIL | NIL | | 8 | 14 | 6 | 2 | | 9 | 21 | NIL | NIL | | 10 | 5 | NIL | NIL |
Answer
10.4-2 Write an $O(n)$-time recursive procedure that, given an n-node binary tree, prints out the key of each node in the tree.
Answer
PRINT-BINARY-TREE(T)
if T.root != NIL
PRINT-NODE(T.root)
PRINT-NODE(x)
print x.key
if x.left != NIL
PRINT-NODE(x.left)
if x.right != NIL
PRINT-NODE(x.right)
10.4-3 Write an $O(n)$-time nonrecursive procedure that, given an n-node binary tree, prints out the key of each node in the tree. Use a stack as an auxiliary data structure.
Answer
PRINT-BINARY-TREE(T)
let S be a new stack
PUSH(S, T.root)
while !STACK-EMPTY(S)
x = S[S.top]
while x != NIL
PUSH(S, x.left)
x = S[S.top]
POP(S)
if !STACK-EMPTY(S)
x = POP(S)
print x.key
PUSH(S, x.right)
10.4-4 Write an $O(n)$-time procedure that prints all the keys of an arbitrary rooted tree with n nodes, where the tree is stored using the left-child, right-sibling representation.
Answer
PRINT-TREE(T)
if T.root != NIL
PRINT-TREE-NODE(T.root)
PRINT-TREE-NODE(x)
print x.key
if x.left-child != NIL
PRINT-TREE-NODE(x.left-child)
if x.right-sibling != NIL
PRINT-TREE-NODE(x.right-sibling)
10.4-5 * Write an $O(n)$-time nonrecursive procedure that, given an n-node binary tree, prints out the key of each node. Use no more than constant extra space outside of the tree itself and do not modify the tree, even temporarily, during the procedure.
Answer
PRINT-BINARY-TREE(T)
x = T.root
prev = NIL
while x != NIL
if prev == x.parent
print x.key
prev = x
if x.left != NIL
x = x.left
else if x.right != NIL
x = x.right
else
x = x.parent
else if prev == x.left and x.right != NIL
prev = x
x = x.right
else
prev = x
x = x.parent
10.4-6 The left-child, right-sibling representation of an arbitrary rooted tree uses three pointers in each node: left-child, right-sibling, and parent. From any node, its parent can be reached and identified in constant time and all its children can be reached and identified in time linear in the number of children. Show how to use only two pointers and one boolean value in each node so that the parent of a node or all of its children can be reached and identified in time linear in the number of children.
Answer Use a boolean to determine a node is whether the last sibling or not. The right-sibling of the last sibling points at its parent.
Problem
10-1 Comparisons among lists For each of the four types of lists in the following table, what is the asymptotic worst-case running time for each dynamic-set operation listed?
Answer
unsorted, singly linked
sorted, singly linked
unsorted, doubly linked
sorted, doubly linked
SEARCH(L,k)
$\Theta(n)$
$\Theta(n)$
$\Theta(n)$
$\Theta(n)$
INSERT(L,x)
$\Theta(1)$
$\Theta(n)$
$\Theta(1)$
$\Theta(n)$
DELETE(L,x)
$\Theta(n)$
$\Theta(n)$
$\Theta(1)$
$\Theta(1)$
SUCCESSOR(L,x)
$\Theta(n)$
$\Theta(1)$
$\Theta(n)$
$\Theta(1)$
PREDECESSOR(L,x)
$\Theta(n)$
$\Theta(n)$
$\Theta(n)$
$\Theta(1)$
MINIMUM(L)
$\Theta(n)$
$\Theta(1)$
$\Theta(n)$
$\Theta(1)$
MAXIMUM(L)
$\Theta(n)$
$\Theta(n)$
$\Theta(n)$
$\Theta(1)$
10-2 Mergeable heaps using linked lists A mergeable heap supports the following operations: MAKE-HEAP (which creates an empty mergeable heap), INSERT, MINIMUM, EXTRACT-MIN, and UNION. Show how to implement mergeable heaps using linked lists in each of the following cases. Try to make each operation as efficient as possible. Analyze the running time of each operation in terms of the size of the dynamic set(s) being operated on. a. Lists are sorted. b. Lists are unsorted. c. Lists are unsorted, and dynamic sets to be merged are disjoint.
Answer TODO
11. Hash Tables
A hash table is an effective data structure for implementing dictionaries. Although seaching for an element in a hash table can take as long as searching for an element in a linked list—$\Theta(n)$ time in the worst case—in practive, hashing performs extremely well. Under reasonable assumptions, the average time to search for an element in a hash table is $O(1)$.
11.1 Direct-address tables
Direct addressing is a simple technique that works well when the universe U of keys is reasonably small. To represent the dynamic set, we use an array, or direct-address table, denoted by T[0…m-1], in which each position, or slot, corresponds to a key in the universe U.
11.1-1 Suppose that a dynamic set S is represented by a direct-address table T of length m. Describe a procedure that finds the maximum element of S. What is the worst-case performance of your procedure?
Answer
MAXIMUM(T)
for i=m downto 1
x = DIRECT-ADDRESS-SEARCH(T,i)
if x != NIL
return x
return NIL
Worst-case running time: $O(n)$.
11.1-2 A bit vector is simply an array of bits (0s and 1s). A bit vector of length m takes much less space than an array of m pointers. Describe how to use a bit vector to represent a dynamic set of distinct elements with no satellite data. Dictionary operations should run in $O(1)$ time.
Answer The bit tells whether the element is in the array.
11.1-3 Suggest how to implement a direct-address table in which the keys of stored elements do not need to be distinct and the elements can have satellite data. All three dictionary operations (INSERT, DELETE, and SEARCH) should run in $O(1)$ time. time. (Don’t forget that DELETE takes as an argument a pointer to an object to be deleted, not a key.)
Answer Map every key to a doubly linked list.
11.1-4 * We wish to implement a dictionary by using direct addressing on a huge array. At the start, the array entries may contain garbage, and initializing the entire array is impractical because of its size. Describe a scheme for implementing a direct-address dictionary on a huge array. Each stored object should use $O(1)$ space; the operations SEARCH, INSERT, and DELETE should take $O(1)$ time each; and initializing the data structure should take $O(1)$ time. (Hint: Use an additional array, treated somewhat like a stack whose size is the number of keys actually stored in the dictionary, to help determine whether a given entry in the huge array is valid or not.)
Answer In order to implement a dictionary using a huge array denoted as A, we need a stack-like validity array denoted as V, which will keep track of the validity of the entries in the huge array.
SEARCH: To check if a key exists in the dictionary, we check the index=key. If index is within the bounds of A and A[index] holds a valid value, we return A[index]. Otherwise return NIL.
INSERT: Set A[index] to key and push index onto the validity array V.
DELETE: We need to check if A[index] holds the value key. If so, set A[index] to NIL and pop the last index from the validity array V.
10.2 Hash tables
The downside of direct addressing is obvious: if the universe U is large, storing a table T of size |U| may be impractical, or even impossible, given the memory available on a typical computer.
When the set K of keys stored in a ditctionary is much smaller than the universe U of all possible keys, a hash table requires much less storage than a direct-address table. With direct addressing, an element with key k is stored in slot k. With hashing, this element is stored in slot $h(k)$; that is, we use a hash functionh to compute the slot from the key k. Here, h maps the universe U of keys into the slots of a hash table T[0…m-1]: $$ h:U \to \lbrace 0,1,…,m-1 \rbrace $$ where the size m of the hash table is typically much less than |U| We say that an element with key k hashes to slot $h(k)$; we also say that $h(k)$ is the hash value of key k.
There is one hitch: two keys may hash to the same slot. We call this situation a collision. Fortunately, we have effective techniques for resolving the conflict created by collisions. Of course, the ideal solution would be to avoid collisions. One idea is to make the hash function h appear to be “random”, thus avoid collisions or at least minimizing their number.
Collision resolution by chaining
In chaining, we place all the elements that hash to the same slot into the same linked list. Slot j contains a pointer to the head of the list of all stored elements that hash to j; if there are no such elements, slot j contains NIL.
CHAINED-HASH-INSERT(T,x)
insert x at the head of list T[h(x.key)]
CHAINED-HASH-SEARCH(T,k)
search for an element with key k in list t[H(k)]
CHAINED-HASH-DELETE(T,x)
delete x from the list T[h(x.key)]
The worst-case running time for insertion is $O(1)$. We can delete an element in $O(1)$ time if the lists are doubly linked. Note that the deletion is for the element x, not the key k. So we can delete from list by accessing the pointer prev and next, which takes only $O(1)$ time. How long does hashing with chaining take to search for an element with a given key?
Analysis of hashing with chaining
Given a hash table T with m slots that stores n elements, we define the load factorα for T as $\frac{n}{m}$, that is, the average number of elements stored in a chain.
The worst-case behavior of hashing with chaining is terrible: all n keys hash to the same slot, creating a list of length n. So the worst-case time for searching is thus $\Theta(n)$ plus the time to compute the hash function—no better than if we used one linked list for all the elements
The average-case performance of hashing depends on how well the hash function h distributes the set of keys to be stored among the m slots, on the average. We shall assume that any given element is equally likely to hash into any of the m slots, independently of where any other element has hashed to. We call this the assumption of simple uniform hashing. $$ \begin{align} & \quad \text{For } j=0,1,…,m-1 \text{, let us denote the length of the list } T[j] \text{ by } n_j \text{, so that} \\ & n = n_0 + n_1 + \cdots + n_{m-1} \tag{11.1} \end{align} $$ and the expected value of $n_j$ is $E[n_j] = \alpha = \frac{n}{m}$.
We assume that $O(1)$ time suffices to compute the hash value $h(k)$, so that the time required to search for an element with key k depends linearly on the length $n_{h(k)}$ of the list $T[h(k)]$. Setting aside the $O(1)$ time required to compute the hash function and to access slot $h(k)$, let us consider the expected number of elements examined by the search algorithm, that is, the number of elements in the list $T[h(k)]$ that the algorithm checks to see whether any have a key equal to k. We shall consider two cases. In the first, the search is unsuccessful: no element in the table has key k. In the second, the search successfully finds an element with key k.
Theorem 11.1 In a hash table in which collisions are resolved by chaining, an unsuccessful search takes average-case time $\Theta(1+\alpha)$,under the assumption of simple uniform hashing. Proof Under the assumption of simple uniform hashing, any key k not already stored in the table is equally likely to hash to any of the m slots. The expected time to search unsuccessfully for a key k is the expected time to search to the end of list $T[h(k)]$, which has expected length $E[n_{h(k)}] = \alpha$. Thus, the expected number of elements examined in an unsuccessful search is α, and the total time required (including the time for computing $h(k)$) is $\Theta(1+\alpha)$.
Theorem 11.2 In a hash table in which collisions are resolved by chaining, a successful search takes average-case time $\Theta(1+\alpha)$, under the assumption of simple uniform hashing. Proof We assume that the element being searched for is equally likely to be any of the n elements stored in the table. The number of elements examined during a successful search for an element x is one more than the number of elements that appear before x in x‘s list. Because new elements are placed at the front of the list, elements before x in the list were all inserted after x was inserted. To find the expected number of elements examined, we take the average, over the n elements x in the table, of 1 plus the expected number of elements added to x’s list after x was added to the list. Let $x_i$ denote the ith element inserted into the table, for $i=1,2,…,n$, and let $k_i = x_i.key$. For keys $k_i$ and $k_j$, we define the indicator random variable $X_{ij} = I \lbrace h(k_i)=h(k_j) \rbrace$. Under the assumption of simple uniform hashing, we have $Pr \lbrace h(k_i)=h(k_j) \rbrace = \frac{1}{m}$, and so by Lemma 5.1, $E[X_{ij}] = \frac{1}{m}$. Thus, the expected number of elements examined in a successful search is $$ \begin{align} &\quad E\left[\frac{1}{n}\sum_{i=1}^n\left(1+\sum_{j=i+1}^n X_{ij}\right)\right] \\ &= \frac{1}{n}\sum_{i=1}^n\left(1+\sum_{j=i+1}^n E[X_{ij}]\right) && \text{(by linearity of expectation)} \\ &= \frac{1}{n}\sum_{i=1}^n\left(1+\sum_{j=i+1}^n \frac{1}{m}\right) \\ &= 1 + \frac{1}{nm}\sum_{i=1}^n(n-i) \\ &= 1 + \frac{1}{nm}\left(\sum_{i=1}^n n - \sum_{i=1}^n i \right) \\ &= 1 + \frac{1}{nm}\left(n^2 - \frac{n(n+1)}{2} \right) && \text{(by equation (A.1))} \\ &= 1 + \frac{n-1}{2m} \\ &= 1 + \frac{\alpha}{2} - \frac{\alpha}{2n} \end{align} $$ Thus, the total time required for a successful search (including the time for computing the hash function) is $\Theta(1 + 1 + \frac{\alpha}{2} - \frac{\alpha}{2n}) = \Theta(1 + \alpha)$. If the number of hash-table slots is at least proportional to the number of elements in the table, we have $n=O(m)$ and, consequently, $\alpha = \frac{n}{m} = \frac{O(m)}{m} = O(1)$. Thus, searching takes constant time on average.
Exercises
11.2-1 Suppose we use a hash function h to hash n distinct keys into an array T of length m. Assuming simple uniform hashing, what is the expected number of collisions? More precisely, what is the expected cardinality of $\lbrace\lbrace k,l \rbrace : k \ne l \text{ and } h(k)=h(l) \rbrace$?
Answer Under the assumption of simple uniform hashing, any given element is equally likely to hash into any of the m slot, so for each element, the possibility of hashing into a specific slot is $\frac{1}{m}$. If a collision occurs, there are two or more elements being hashed into the same slot. In order to find all the cases when collisions occur, we can find every pair hashing to the same slot. If 3 elements hashing to the same slot, e.g. element 1,2 and 3, three collisions occur, and in this case the pairs are (1,2), (1,3), (2,3). So we just need to find all the possible pairs. It’s $$ \binom{n}{2} = \frac{n!}{2(n-2)!} = \frac{n(n-1)(n-2)!}{2(n-2)!} = \frac{n(n-1)}{2} $$ Therefore, the expected number of collisions is the total pairs times the probability for each pair to collide: $$ E[C] = \frac{n(n-1)}{2} \cdot \frac{1}{m} = \frac{n(n-1)}{2m} $$
11.2-2 Demonstrate what happens when we insert the keys 5,28,19,15,20,33,12,17,10 into a hash table with collisions resolved by chaining. Let the table have 9 slots, and let the hash function be $h(k) = k \mod 9$.
11.2-3 Professor Marley hypothesizes that he can obtain substantial performance gains by modifying the chaining scheme to keep each list in sorted order. How does the professor’s modification affect the running time for successful searches, unsuccessful searches, insertions, and deletions?
Answer
Successful searches: no difference, still $\Theta(1+\alpha)$.
Unsuccessful searches: faster, since the searching can stop after desirable key is greater or less than the checking key. However, the order of growth for running time is unchanged: $\Theta(1+\alpha)$.
Insertions: slower, since we need to find an appropriate position for the element to insert into the list: $\Theta(1 + \alpha)$, where α is the time to find the appropriate position to insert.
deletions: unchanged for doubly linked list: $\Theta(1+\alpha)$.
11.2-4 Suggest how to allocate and deallocate storage for elements within the hash table itself by linking all unused slots into a free list. Assume that one slot can store a flag and either one element plus a pointer or two pointers. All dictionary and free-list operations should run in $O(1)$ expected time. Does the free list need to be doubly linked, or does a singly linked free list suffice?
Answer A flag is required to determine whether a slot contains an element. In order to make the free-list operations run in $O(1)$ expected time, the free list need to be doubly linked.
11.2-5 Suppose that we are storing a set of n keys into a hash table of size m. Show that if the keys are drawn from a universe U with $|U| > nm$, then U has a subset of size n consisting of keys that all hash to the same slot, so that the worst-case searching time for hashing with chaining is $\Theta(n)$.
Answer If $|U| > nm$, then there is at least one slot containing a list of more than n elements. Searching in this list takes $\Theta(n)$ time.
11.2-6 Suppose we have stored n keys in a hash table of size m, with collisions resolved by chaining, and that we know the length of each chain, including the length L of the longest chain. Describe a procedure that selects a key uniformly at random from among the keys in the hash table and returns it in expected time $O(L \cdot (1 + \frac{1}{\alpha}))$.
Answer We define $\alpha = \frac{n}{m}$, so we need to find a procedure running in expected time $O(L \cdot (1 + \frac{m}{n}))$.
TODO
11.3 Hash functions
12. Binary Search Trees
PART VI: GRAPH ALGORITHMS
22. Elementary Graph Algorithms
23. Minimum Spanning Trees
24. Single-Source Shortest Paths
25. All-Pairs Shortest Paths
PART VII: SELECTED TOPICS
32. String Matching
99. Terminologies in English and Chinese
The terminologies in 3.2 has been extracted because they are basic mathematical terms. You can find the terminologies for 3.2 Standard Notations and Common FunctionsHERE